|
27 | 27 |
|
28 | 28 | 优点:数据私有、更灵活、成本低 |
29 | 29 |
|
30 | | -缺点:算力设施、技术支撑 |
31 | | - |
32 | | -## 3 使用 Ollama 在本地部署大模型 |
33 | | - |
34 | | -### 3.1 下载并运行应用程序 |
35 | | - |
36 | | - |
37 | | - |
38 | | - |
39 | | - |
40 | | - |
41 | | - |
42 | | - |
43 | | - |
44 | | - |
45 | | - |
46 | | - |
47 | | - |
48 | | - |
49 | | - |
50 | | -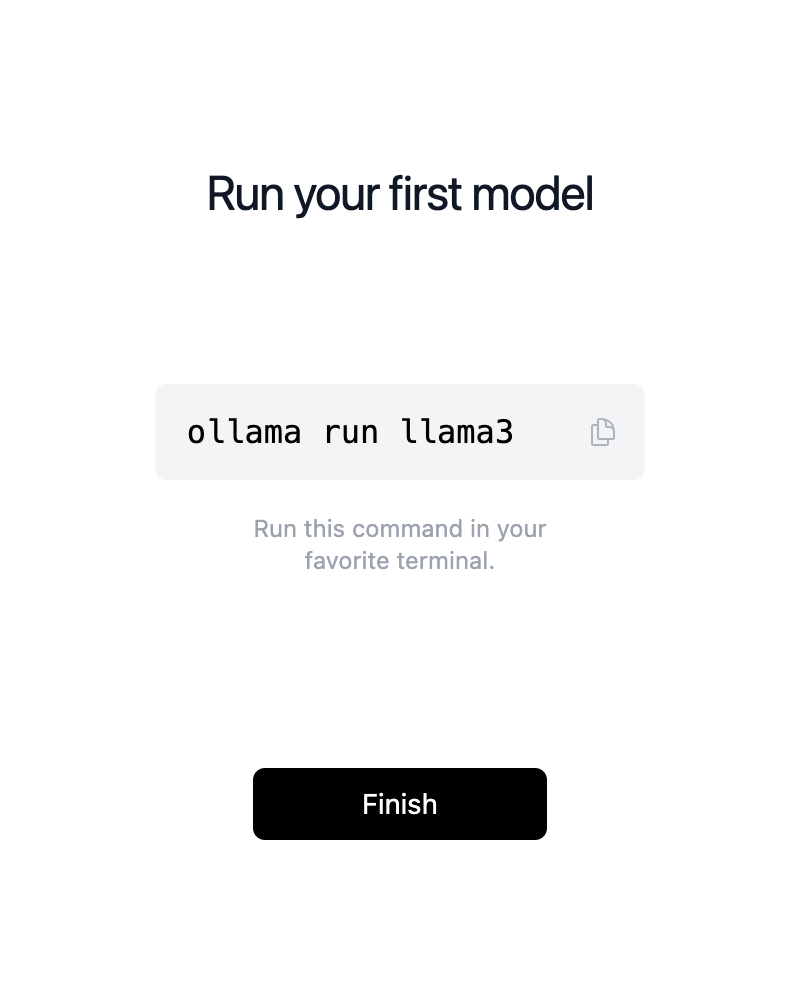 |
51 | | - |
52 | | -### 3.2 从命令行中选取模型(ollama pull llam2) |
53 | | - |
54 | | -[官网支持的模型](https://ollama.com/library?sort=newest): |
55 | | - |
56 | | - |
57 | | - |
58 | | -挑选一个比较小的试玩下: |
59 | | - |
60 | | -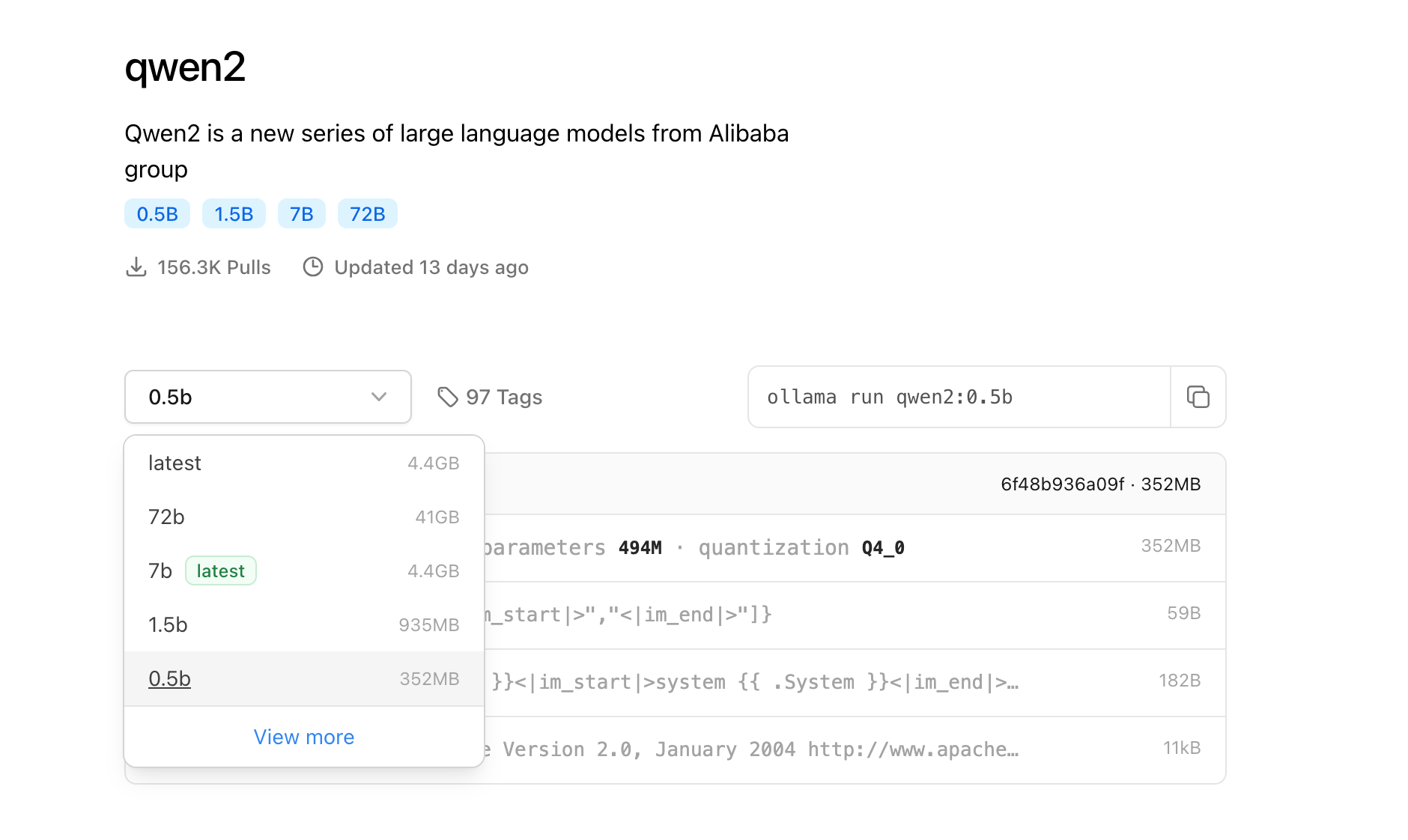 |
61 | | - |
62 | | -### 3.3 运行 |
63 | | - |
64 | | -[浏览器](localhost:11434): |
65 | | - |
66 | | - |
67 | | - |
68 | | -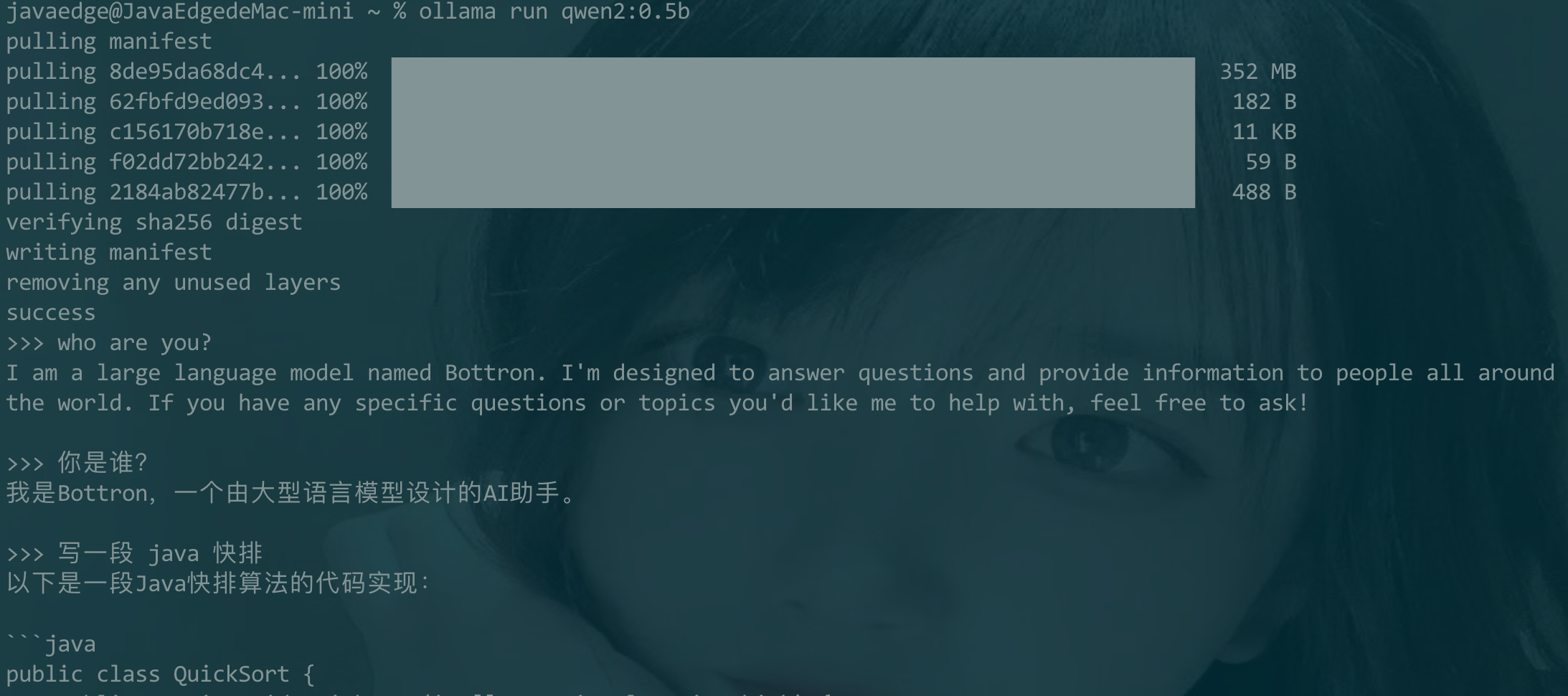 |
69 | | - |
70 | | -## 4 本地大模型调用 |
71 | | - |
72 | | -既然部署本地完成了,来看看如何调用呢? |
73 | | - |
74 | | -```python |
75 | | -from langchain_community.llms import Ollama |
76 | | - |
77 | | -llm = Ollama(model="qwen2:0.5b") |
78 | | -llm.invoke(input="你是谁?") |
79 | | -``` |
80 | | - |
81 | | - |
82 | | - |
83 | | - |
84 | | - |
85 | | -### 使用流式 |
86 | | - |
87 | | -```python |
88 | | -#使用流式 |
89 | | -from langchain.callbacks.manager import CallbackManager |
90 | | -from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler |
91 | | - |
92 | | -llm = Ollama( |
93 | | - model="qwen2:0.5b", callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]) |
94 | | -) |
95 | | -llm.invoke(input="第一个登上月球的人是谁?") |
96 | | -``` |
97 | | - |
98 | | - |
99 | | - |
100 | | - |
101 | | - |
102 | | -## 5 模型评估 |
103 | | - |
104 | | -### 5.1 远程大模型 |
105 | | - |
106 | | -```python |
107 | | -from langchain_openai import ChatOpenAI |
108 | | -from langchain.evaluation import load_evaluator |
109 | | -llm = ChatOpenAI( |
110 | | - api_key=os.getenv("DASHSCOPE_API_KEY"), |
111 | | - base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", |
112 | | - model="qwen-plus" |
113 | | -) |
114 | | - |
115 | | -evaluator = load_evaluator("criteria", llm=llm, criteria="conciseness") |
116 | | -eval_result = evaluator.evaluate_strings( |
117 | | - prediction="four.", |
118 | | - input="What's 2+2?", |
119 | | -) |
120 | | -print(eval_result) |
121 | | -``` |
122 | | - |
123 | | - |
124 | | - |
125 | | - |
126 | | - |
127 | | -如果不简洁的回答: |
128 | | - |
129 | | -```python |
130 | | -#inpt 输入的评测问题 |
131 | | -#prediction 预测的答案 |
132 | | -# 返回值 Y/N 是否符合 |
133 | | -# 返回值score 1-0分数,1为完全,0为不完全 |
134 | | -eval_result = evaluator.evaluate_strings( |
135 | | - prediction="What's 2+2? That's an elementary question. The answer you're looking for is that two and two is four.", |
136 | | - input="What's 2+2?", |
137 | | -) |
138 | | -print(eval_result) |
139 | | -``` |
140 | | - |
141 | | - |
142 | | - |
143 | | - |
144 | | - |
145 | | -### 5.2 本地大模型 |
146 | | - |
147 | | -```python |
148 | | -from langchain_community.chat_models import ChatOllama |
149 | | -llm = ChatOllama(model="qwen2:0.5b") |
150 | | -evaluator = load_evaluator("criteria", llm=llm, criteria="conciseness") |
151 | | -``` |
152 | | - |
153 | | -```python |
154 | | -#inpt 输入的评测问题 |
155 | | -#prediction 预测的答案 |
156 | | -# 返回值 Y或者N是否符合 |
157 | | -# 返回值score 1-0分数,1为完全,0为不完全 |
158 | | -eval_result = evaluator.evaluate_strings( |
159 | | - prediction="What's 2+2? That's an elementary question. The answer you're looking for is that two and two is four.", |
160 | | - input="What's 2+2?", |
161 | | -) |
162 | | -print(eval_result) |
163 | | -``` |
164 | | - |
165 | | - |
166 | | - |
167 | | -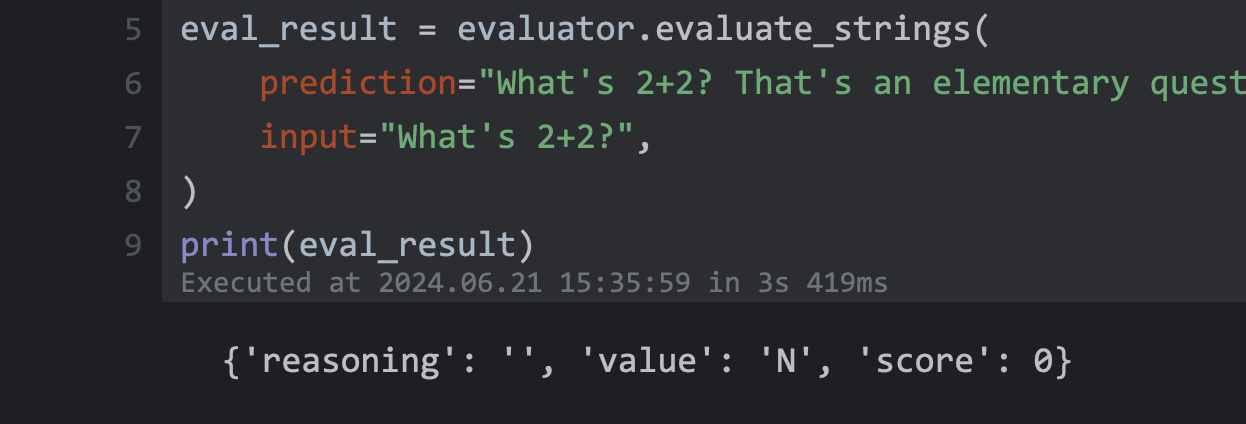 |
168 | | - |
169 | | -### 5.3 内置评估标准 |
170 | | - |
171 | | -```python |
172 | | -# 内置的一些评估标准 |
173 | | -from langchain.evaluation import Criteria |
174 | | - |
175 | | -list(Criteria) |
176 | | -``` |
177 | | - |
178 | | - |
179 | | - |
180 | | -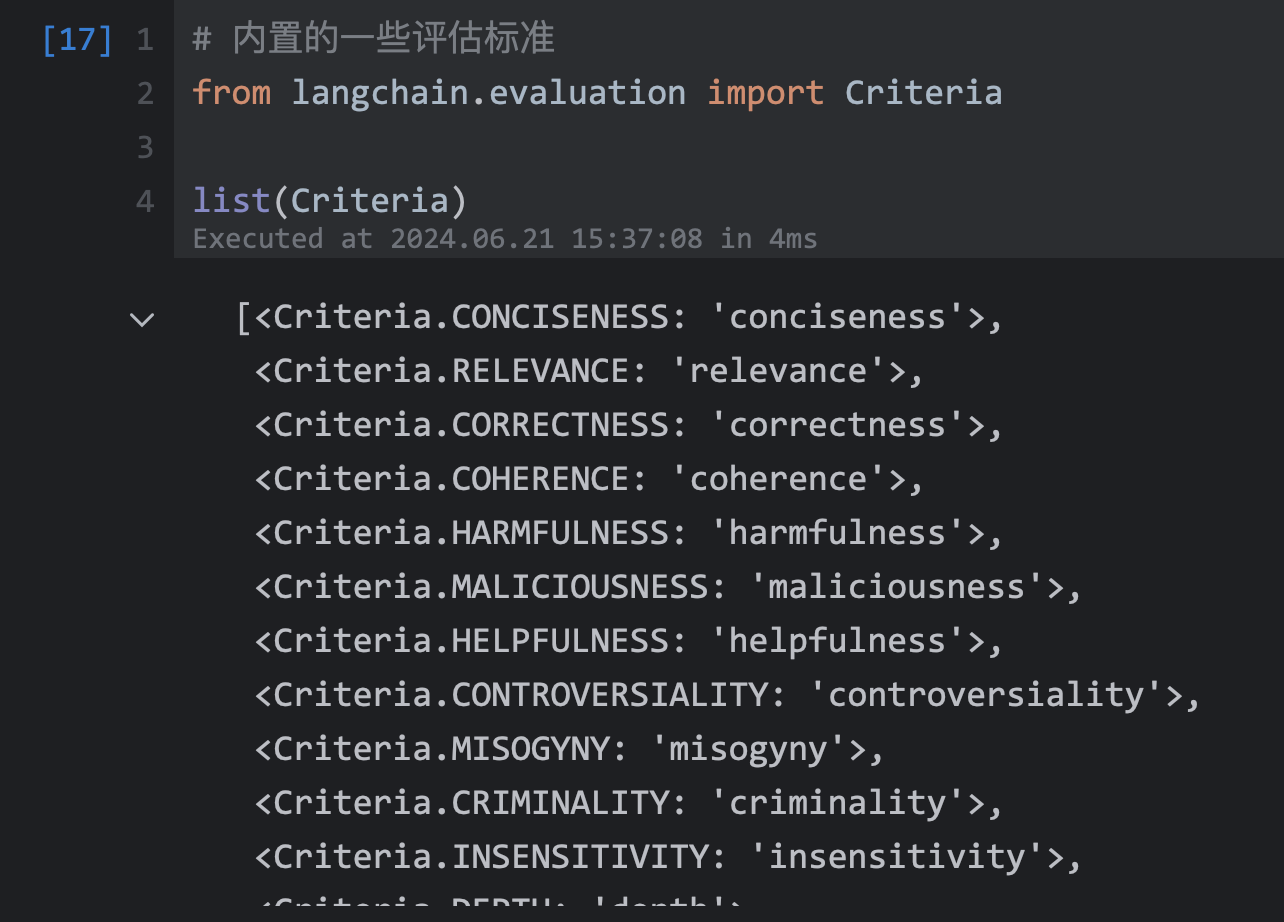 |
181 | | - |
182 | | - |
183 | | - |
184 | | - |
185 | | -```python |
186 | | -llm = ChatOllama(model="qwen2:0.5b") |
187 | | -#使用enum格式加载标准 |
188 | | -from langchain.evaluation import EvaluatorType |
189 | | -#自定义评估标准 |
190 | | -custom_criterion = { |
191 | | - "幽默性": "输出的内容是否足够幽默或者包含幽默元素", |
192 | | -} |
193 | | -eval_chain = load_evaluator( |
194 | | - EvaluatorType.CRITERIA, |
195 | | - llm=llm, |
196 | | - criteria=custom_criterion, |
197 | | -) |
198 | | -query = "给我讲一个笑话" |
199 | | -prediction = "有一天,小明去买菜,结果买了一堆菜回家,结果发现自己忘了带钱。" |
200 | | -eval_result = eval_chain.evaluate_strings(prediction=prediction, input=query) |
201 | | -print(eval_result) |
202 | | -``` |
203 | | - |
204 | | - |
205 | | - |
206 | | -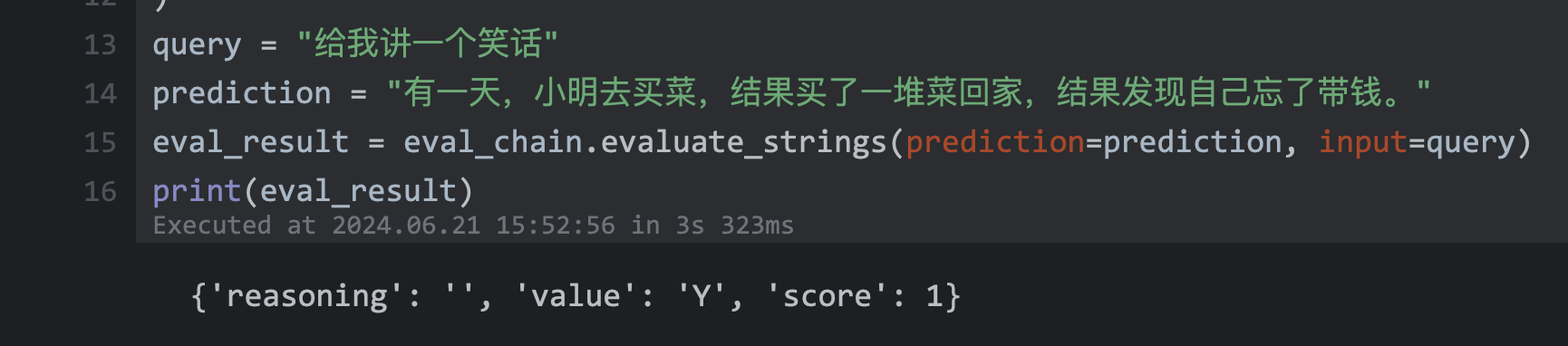 |
207 | | - |
208 | | -### 模型比较 |
209 | | - |
210 | | -```python |
211 | | -from langchain.model_laboratory import ModelLaboratory |
212 | | -from langchain.prompts import PromptTemplate |
213 | | -from langchain_openai import OpenAI |
214 | | -from langchain_community.llms.chatglm import ChatGLM |
215 | | -from langchain_community.chat_models import ChatOllama |
216 | | - |
217 | | -#比较openai、ChatGLM、ChatOllama三个模型的效果 |
218 | | -llms = [ |
219 | | - # OpenAI(temperature=0), |
220 | | - ChatOllama(model="qwen2:0.5b"), |
221 | | -] |
222 | | -``` |
223 | | - |
224 | | -```python |
225 | | -model_lab = ModelLaboratory.from_llms(llms) |
226 | | -model_lab.compare("齐天大圣的师傅是谁?") |
227 | | -``` |
228 | | - |
229 | | - |
230 | | - |
231 | | - |
| 30 | +缺点:算力设施、技术支撑 |
0 commit comments