

@@ -16,6 +12,8 @@ Score a batch with a built-in eval, find the rows where it scored differently th
|------|-----------|---------|
| 15 min | Intermediate | `ai-evaluation` |
+By the end of this cookbook you will have a custom eval that catches failures a generic eval misses (off-policy refund offers, upsells in support replies, anything that violates your team's domain rules), 100% agreement with human verdicts on a four-row demo batch where the baseline scored 50%, and a repeatable loop to recalibrate after every prompt change. The only application-code change is one API call to register the new eval template.
+
- FutureAGI account → [app.futureagi.com](https://app.futureagi.com)
- API keys: `FI_API_KEY` and `FI_SECRET_KEY` (see [Get your API keys](/docs/admin-settings))
@@ -35,14 +33,16 @@ export FI_API_KEY="your-fi-api-key"
export FI_SECRET_KEY="your-fi-secret-key"
```
-## Tutorial
+## What is an eval correction loop?
-The example below uses SaaS customer-support replies. The trick: pick failure modes a generic eval can't catch. A reply that pitches an upsell, commits a front-line agent to a refund, or recommends disabling 2FA can sound polished and on-topic. A generic helpfulness eval rates the surface form. Your team's rules rate what the reply *should not* do. The correction loop closes that gap.
+Built-in evals like `is_helpful` or `tone` score the **surface form** of a response. They have no way to know your refund-escalation policy, your no-upsell rule, or your security team's blocklist. So a reply that looks polite, on-topic, and complete will pass a generic eval even when your team would flag it as bad.
+
+The correction loop closes that gap in five steps: score a batch with a generic eval, mark the rows where the eval and your team disagree, encode those disagreements as few-shot FAIL examples in a custom rule prompt, re-score to verify the eval now matches your judgment, and iterate until fresh batches stay above your agreement bar. The example below runs the full loop on a four-row SaaS support batch where the bad replies look helpful but violate domain rules a generic eval cannot see.
-Start with a built-in template like `is_helpful` or `tone`. It gives you a baseline plus the explanations the judge model used. The explanations are what you'll inspect in step 2.
+Start with a built-in template that scores the **surface form** of the response (`is_helpful`, `tone`, `coherence`). These are the evals most likely to pass replies your team would fail, because they have no way to know your domain rules. That's exactly the gap the correction loop closes. Run on a small batch (4 to 10 rows is enough for the first pass) and capture both the verdict AND the judge's reason. The reasons tell you whether the eval missed your domain rules or correctly applied them.
```python
import os
@@ -106,7 +106,7 @@ The built-in `is_helpful` eval will likely return `Passed` for `r2` and `r3`. Bo
-A disagreement is any row where the eval and the human reach different verdicts. Sort by these. They're the rows that teach the evaluator something new.
+The rows where the eval and human agree don't teach the eval anything new. The rows where they disagree are the entire point: they are the failure modes the generic eval can't see. Sort those out, then look at the judge's reason for each disagreement. The reason explains WHY the surface form passed the generic eval, which tells you exactly what your custom rule prompt needs to forbid.
```python
def passed(score):
@@ -123,12 +123,12 @@ for r in disagreements:
print(f" reason: {r['eval_reason'][:120]}")
```
-Pick 2 or 3 disagreement rows that capture distinct failure modes (here: cheerful-but-empty replies, off-policy promises). Those become your few-shot examples in the next step.
+Pick 2 or 3 disagreement rows that capture distinct failure modes (here: out-of-policy refund commits, in-support upsells). Those become your few-shot examples in the next step.
-Create a custom eval whose rule prompt spells out your domain's definition of "good" and includes the corrected examples inline. The judge model uses the examples to calibrate its decisions on new rows.
+A custom eval is just a rule prompt plus an output type. The rule prompt has two jobs. First, enumerate your domain rules in plain English so the judge model has criteria instead of vibes. Second, include 1 to 3 few-shot examples of FAILs your team has flagged so the judge knows what "FAIL" actually looks like in *your* domain. One API call to `/model-hub/create_custom_evals/` registers the template. Future eval calls reference it by name.
```python
import requests
@@ -189,7 +189,7 @@ Version your eval names (`_v1`, `_v2`). Each iteration creates a new template so
-Run the new eval on the same samples and compare against your human verdicts.
+Re-score the **same** batch with the new eval. Same samples, same human verdicts, only the evaluator changed, so any agreement delta is fully attributable to your rule prompt. Track the percentage of rows where eval and human agree. That's your calibration metric and the number you'll watch climb across iterations.
```python
calibrated_results = []
@@ -219,12 +219,14 @@ Expect a jump from around 50% baseline to 100% on this set. `r2` and `r3` now fa
-If agreement is still below where you need it (typical bar: 85%+ on a held-out batch), the loop continues.
+One pass rarely catches every failure mode. New disagreements on fresh batches are the signal that your rule prompt missed a category. The loop continues with disciplined stop rules: don't add an example for an edge case the eval already gets right (it adds prompt length without changing behavior), and don't bloat past 8 to 10 examples (past that, agreement gains plateau and inference cost keeps growing).
+
+If agreement is still below where you need it (typical bar: 85%+ on a held-out batch):
1. Pull a fresh sample of 20 to 30 rows the eval hasn't seen.
2. Re-score with the latest version (`support_reply_quality_v1`).
3. Find the new disagreements. These are failure modes your rule prompt didn't cover.
-4. Rev to `_v2`: add 1 or 2 new few-shot examples or sharpen one of the rules. Avoid bloating. Every example added trades calibration for prompt length and inference cost.
+4. Rev to `_v2`: add 1 or 2 new few-shot examples or sharpen one of the rules.
```python
# After collecting fresh disagreements...
@@ -238,15 +240,24 @@ Additional FAIL example (learn from this):
# Re-register as support_reply_quality_v2 and compare scores side-by-side.
```
-A well-calibrated eval typically converges in 2 or 3 iterations. Stop when fresh batches stay above your agreement bar. Adding more examples beyond that hurts more than it helps.
+A well-calibrated eval typically converges in 2 or 3 iterations. Stop when fresh batches stay above your agreement bar.
+## What you solved
+
+Repetitive prompt iteration with no objective signal (the kind every team hits when "is this output good?" depends on policy rules a generic eval can't see) now becomes a measurable loop. You have a domain-calibrated evaluator, a single number (agreement %) to track across prompt changes, and a versioned trail of eval templates so you can compare quality runs head-to-head over time.
+
You ran a built-in eval, found rows where it disagreed with human judgment, encoded those corrections as a custom eval with explicit rules and few-shot failure examples, then re-scored to confirm the eval now matches how your team defines quality.
+- **Generic evals scoring surface form** (instead of domain rules): solved by encoding rules in a custom rule prompt with few-shot FAIL examples
+- **No signal which rows to focus on**: solved by surfacing only the disagreements as the calibration target
+- **Starting from scratch on every prompt change**: solved by versioning the eval template (`_v1`, `_v2`) so old runs stay reproducible
+- **No way to measure if the eval matches your team's bar**: solved by tracking agreement % between eval and human verdict across iterations
+
## Explore further
diff --git a/src/pages/docs/cookbook/mcp/debug-traces-from-ide.mdx b/src/pages/docs/cookbook/mcp/debug-traces-from-ide.mdx
index 3e07374e..7bf55ee5 100644
--- a/src/pages/docs/cookbook/mcp/debug-traces-from-ide.mdx
+++ b/src/pages/docs/cookbook/mcp/debug-traces-from-ide.mdx
@@ -3,26 +3,28 @@ title: "Debug LLM Traces From Your IDE Using Natural Language MCP Queries"
description: "Connect Future AGI's MCP server to Cursor, Claude Code, or VS Code, then debug failing traces, run evals, and annotate spans without leaving your editor."
---
-
-Add the Future AGI MCP server to your IDE with one config line, sign in via OAuth, and ask your AI assistant questions like *"what went wrong with the last failing trace in my support-bot project?"* It pulls span data, runs error analysis, and proposes fixes, all in the same chat where you're writing code.
-
-
| Time | Difficulty |
|------|-----------|
| 10 min | Beginner |
+By the end of this cookbook you will have Future AGI's MCP server connected to your IDE, natural-language access to ~50 trace-debugging tools (search traces, error analysis, span trees, annotations) from the same chat where you write code, and a full failure-detection-to-fix loop you can run without copying a trace ID or opening the dashboard. The only setup is one config line and one OAuth approval.
+
- FutureAGI account → [app.futureagi.com](https://app.futureagi.com)
- A traced project with at least a few traces. If you don't have one, follow [Manual Tracing](/docs/cookbook/quickstart/manual-tracing) to instrument an agent first.
- An MCP-capable IDE: Cursor, Claude Code, VS Code (with the MCP extension), Claude Desktop, or Windsurf
-## Tutorial
+## What is MCP?
+
+MCP (Model Context Protocol) is an open standard for letting AI assistants call external tools. Future AGI's MCP server at `https://api.futureagi.com/mcp` exposes the platform's trace-debugging surface (search, error analysis, span trees, error clusters, tags, annotations) as MCP tools. Connect it to your IDE once, sign in via OAuth, and the AI assistant in your editor can answer questions like *"what went wrong with the last failing trace in my support-bot project?"* by calling those tools directly. It pulls span data, runs analysis, and proposes fixes, all in the same chat where you're writing code.
+
+The four steps below are: register the MCP server with your IDE, complete the one-time OAuth handshake, run example debugging queries against your real traces, then iterate on the fix in the same chat thread.
-The MCP server lives at `https://api.futureagi.com/mcp` and uses OAuth. No API keys to copy around.
+The connect step is one config line per IDE. The URL (`https://api.futureagi.com/mcp`) is the same everywhere, only the file path and JSON shape differ. Once registered, your IDE knows where to route MCP tool calls but doesn't have permission yet. The OAuth handshake in step 2 is what unlocks access to your workspace.
@@ -112,7 +114,9 @@ Restart your IDE after editing the config.
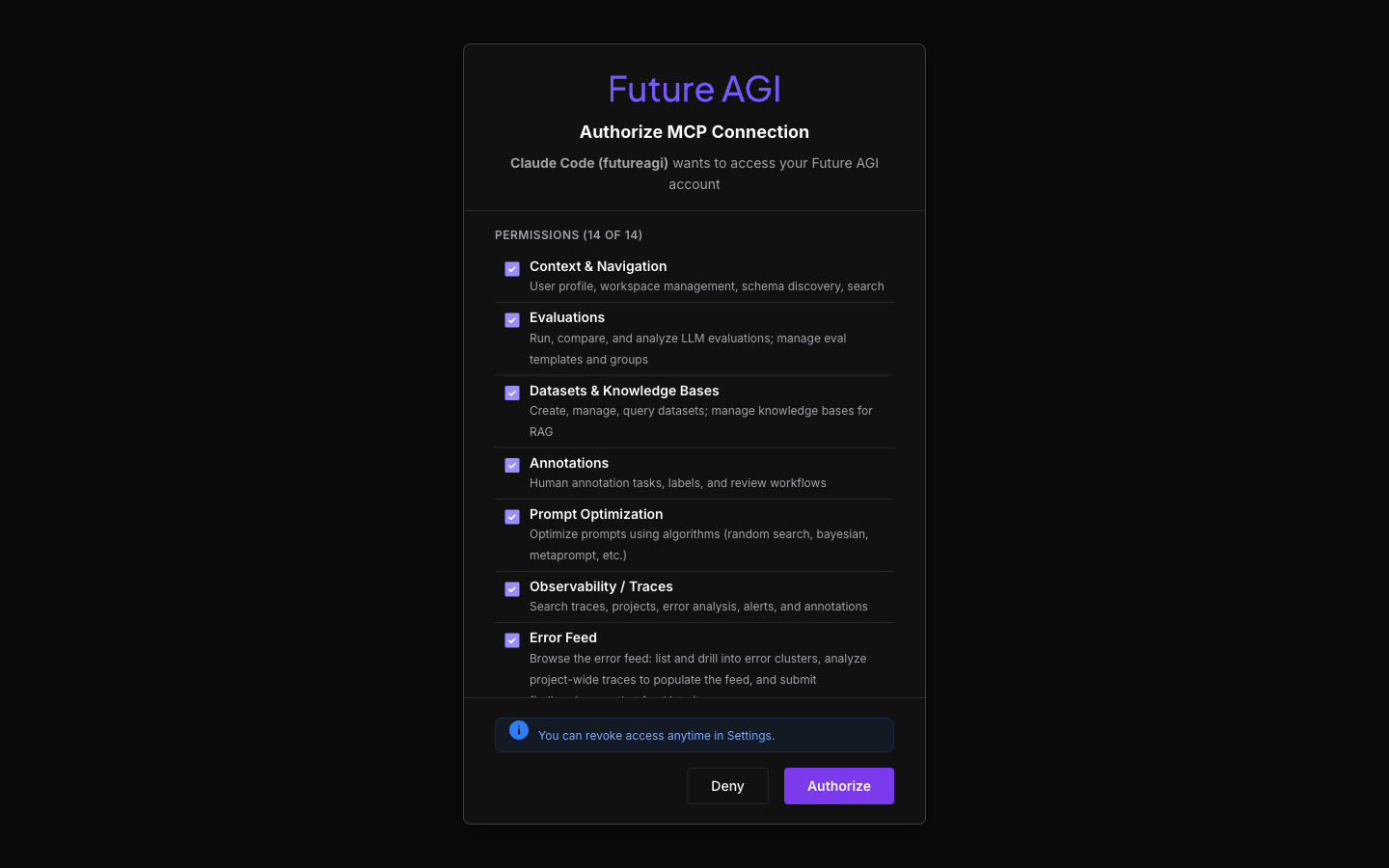
-The first MCP tool call opens a browser to the consent screen. Review the 14 permission groups, click **Authorize**. Token cached, done.
+OAuth instead of API keys means the connection is tied to your user account, scoped to the permission groups you approve, and revocable from the dashboard at any time. No shared keys to rotate, no `.env` to manage. The first MCP tool call your assistant attempts triggers the consent screen automatically.
+
+Click **Authorize**. Token cached. Done.
 @@ -123,7 +127,7 @@ If the browser doesn't open, ask your assistant *"list my Future AGI projects"*
-Open your IDE's chat panel and ask. The MCP server exposes ~50 trace-related tools (search, error analysis, span trees, error clusters), so phrase questions naturally. Your assistant picks the right tools.
+You don't memorize tool names. The MCP server publishes ~50 trace-debugging tools (search, error analysis, span trees, error clusters, tags, annotations), each with a description. Your assistant reads your question against those descriptions and picks the right tool, the right arguments, and chains follow-ups when needed. Five example questions below, each mapped to the tool it actually calls so you can see the pattern.
**Find failing traces:**
@@ -137,7 +141,7 @@ Calls `search_traces` with `has_error=True`. If no traces have raw error flags,
> Show me the span tree for the second trace from the previous list.
-Calls `get_span_tree`. Returns the parent span plus nested LLM/tool calls with timing and inputs.
+Calls `get_span_tree`. Returns the parent span plus nested LLM/tool calls with timing and inputs. The follow-up *"second trace from the previous list"* works because the assistant carries chat context across turns.
**Diagnose what went wrong:**
@@ -149,22 +153,22 @@ Calls `get_trace_error_analysis`. Returns categorized findings (hallucination, w
> Analyze all traces in my project from the last hour and group failures by category.
-Calls `analyze_project_traces` and `list_error_clusters`. Returns a histogram with the dominant error types.
+Calls `analyze_project_traces` and `list_error_clusters`. Returns a histogram with the dominant error types so you can prioritize which one to fix first.
**Score or annotate from chat:**
> Add the tag `needs-policy-grounding` to the failing traces, and annotate them with "fabricated specifics, needs RAG over policy docs."
-Calls `add_trace_tags` + `create_trace_annotation` per matching trace. The annotations show up in the dashboard immediately.
+Calls `add_trace_tags` + `create_trace_annotation` per matching trace. The annotations show up in the dashboard immediately so the rest of your team sees what you flagged.
-The same chat that read the trace can now read your code. Ask:
+This step is the payoff. Diagnosing a trace in the dashboard then coming back to your editor to patch the prompt is two context switches. With MCP, your assistant has both the trace findings (from the MCP server) and your source files (from your editor) in one thread, so it can write the fix grounded in the actual failure.
-> Based on the error analysis, draft a system-prompt patch that refuses to answer policy questions when no grounding tool is available. Show it as a diff against [agent.py](agent.py).
+> Based on the error analysis, draft a system-prompt patch that refuses to answer policy questions when no grounding tool is available. Show it as a diff against `agent.py`.
-Your assistant has both the trace findings (from MCP) and the file (from your editor). It produces a paste-ready diff. Apply it, re-run a few queries through the agent, and ask the next turn:
+Apply the diff, re-run a few queries through the agent, then verify in the same chat:
> Re-check the latest traces in my project and confirm the fabrication category dropped.
@@ -173,10 +177,19 @@ That's the full loop. Failure detection, diagnosis, fix, verification, all drive
+## What you solved
+
+Production trace debugging used to require constant context switches: failing trace in the dashboard, copy the trace ID, drill into spans, switch back to the editor, patch the prompt, redeploy, switch back to the dashboard to verify. With the MCP server connected, the entire loop happens in one chat thread next to your code.
+
You connected Future AGI's MCP server to your IDE, asked natural-language questions about your trace data, and ran an end-to-end debug loop without copying trace IDs or switching to the dashboard.
+- **Tab-switching between editor and dashboard for every trace**: solved by routing all trace queries through your IDE chat
+- **Hand-copying trace IDs to dig into a specific failure**: solved by the assistant carrying chat context (*"the second trace from the previous list"* just works)
+- **Diagnosis and fix happening in two different windows**: solved by giving the assistant both trace data (via MCP) and your source files (via the editor) in one thread
+- **API key sharing for tool access**: solved by per-user OAuth with scoped, revocable permissions
+
## Explore further
diff --git a/src/pages/docs/cookbook/observe/continuous-evals-budget.mdx b/src/pages/docs/cookbook/observe/continuous-evals-budget.mdx
new file mode 100644
index 00000000..3296d7b1
--- /dev/null
+++ b/src/pages/docs/cookbook/observe/continuous-evals-budget.mdx
@@ -0,0 +1,216 @@
+---
+title: "Running Continuous Evals in Production Without Blowing Your Token Budget"
+description: "Score every production trace for hallucination, tone, and policy violations on a tight token budget. Sampling, judge-model tiers, span filters, and alert-driven runs cut eval cost by 80%+ without losing the signal."
+---
+
+
@@ -123,7 +127,7 @@ If the browser doesn't open, ask your assistant *"list my Future AGI projects"*
-Open your IDE's chat panel and ask. The MCP server exposes ~50 trace-related tools (search, error analysis, span trees, error clusters), so phrase questions naturally. Your assistant picks the right tools.
+You don't memorize tool names. The MCP server publishes ~50 trace-debugging tools (search, error analysis, span trees, error clusters, tags, annotations), each with a description. Your assistant reads your question against those descriptions and picks the right tool, the right arguments, and chains follow-ups when needed. Five example questions below, each mapped to the tool it actually calls so you can see the pattern.
**Find failing traces:**
@@ -137,7 +141,7 @@ Calls `search_traces` with `has_error=True`. If no traces have raw error flags,
> Show me the span tree for the second trace from the previous list.
-Calls `get_span_tree`. Returns the parent span plus nested LLM/tool calls with timing and inputs.
+Calls `get_span_tree`. Returns the parent span plus nested LLM/tool calls with timing and inputs. The follow-up *"second trace from the previous list"* works because the assistant carries chat context across turns.
**Diagnose what went wrong:**
@@ -149,22 +153,22 @@ Calls `get_trace_error_analysis`. Returns categorized findings (hallucination, w
> Analyze all traces in my project from the last hour and group failures by category.
-Calls `analyze_project_traces` and `list_error_clusters`. Returns a histogram with the dominant error types.
+Calls `analyze_project_traces` and `list_error_clusters`. Returns a histogram with the dominant error types so you can prioritize which one to fix first.
**Score or annotate from chat:**
> Add the tag `needs-policy-grounding` to the failing traces, and annotate them with "fabricated specifics, needs RAG over policy docs."
-Calls `add_trace_tags` + `create_trace_annotation` per matching trace. The annotations show up in the dashboard immediately.
+Calls `add_trace_tags` + `create_trace_annotation` per matching trace. The annotations show up in the dashboard immediately so the rest of your team sees what you flagged.
-The same chat that read the trace can now read your code. Ask:
+This step is the payoff. Diagnosing a trace in the dashboard then coming back to your editor to patch the prompt is two context switches. With MCP, your assistant has both the trace findings (from the MCP server) and your source files (from your editor) in one thread, so it can write the fix grounded in the actual failure.
-> Based on the error analysis, draft a system-prompt patch that refuses to answer policy questions when no grounding tool is available. Show it as a diff against [agent.py](agent.py).
+> Based on the error analysis, draft a system-prompt patch that refuses to answer policy questions when no grounding tool is available. Show it as a diff against `agent.py`.
-Your assistant has both the trace findings (from MCP) and the file (from your editor). It produces a paste-ready diff. Apply it, re-run a few queries through the agent, and ask the next turn:
+Apply the diff, re-run a few queries through the agent, then verify in the same chat:
> Re-check the latest traces in my project and confirm the fabrication category dropped.
@@ -173,10 +177,19 @@ That's the full loop. Failure detection, diagnosis, fix, verification, all drive
+## What you solved
+
+Production trace debugging used to require constant context switches: failing trace in the dashboard, copy the trace ID, drill into spans, switch back to the editor, patch the prompt, redeploy, switch back to the dashboard to verify. With the MCP server connected, the entire loop happens in one chat thread next to your code.
+
You connected Future AGI's MCP server to your IDE, asked natural-language questions about your trace data, and ran an end-to-end debug loop without copying trace IDs or switching to the dashboard.
+- **Tab-switching between editor and dashboard for every trace**: solved by routing all trace queries through your IDE chat
+- **Hand-copying trace IDs to dig into a specific failure**: solved by the assistant carrying chat context (*"the second trace from the previous list"* just works)
+- **Diagnosis and fix happening in two different windows**: solved by giving the assistant both trace data (via MCP) and your source files (via the editor) in one thread
+- **API key sharing for tool access**: solved by per-user OAuth with scoped, revocable permissions
+
## Explore further
diff --git a/src/pages/docs/cookbook/observe/continuous-evals-budget.mdx b/src/pages/docs/cookbook/observe/continuous-evals-budget.mdx
new file mode 100644
index 00000000..3296d7b1
--- /dev/null
+++ b/src/pages/docs/cookbook/observe/continuous-evals-budget.mdx
@@ -0,0 +1,216 @@
+---
+title: "Running Continuous Evals in Production Without Blowing Your Token Budget"
+description: "Score every production trace for hallucination, tone, and policy violations on a tight token budget. Sampling, judge-model tiers, span filters, and alert-driven runs cut eval cost by 80%+ without losing the signal."
+---
+
+
+
+
+
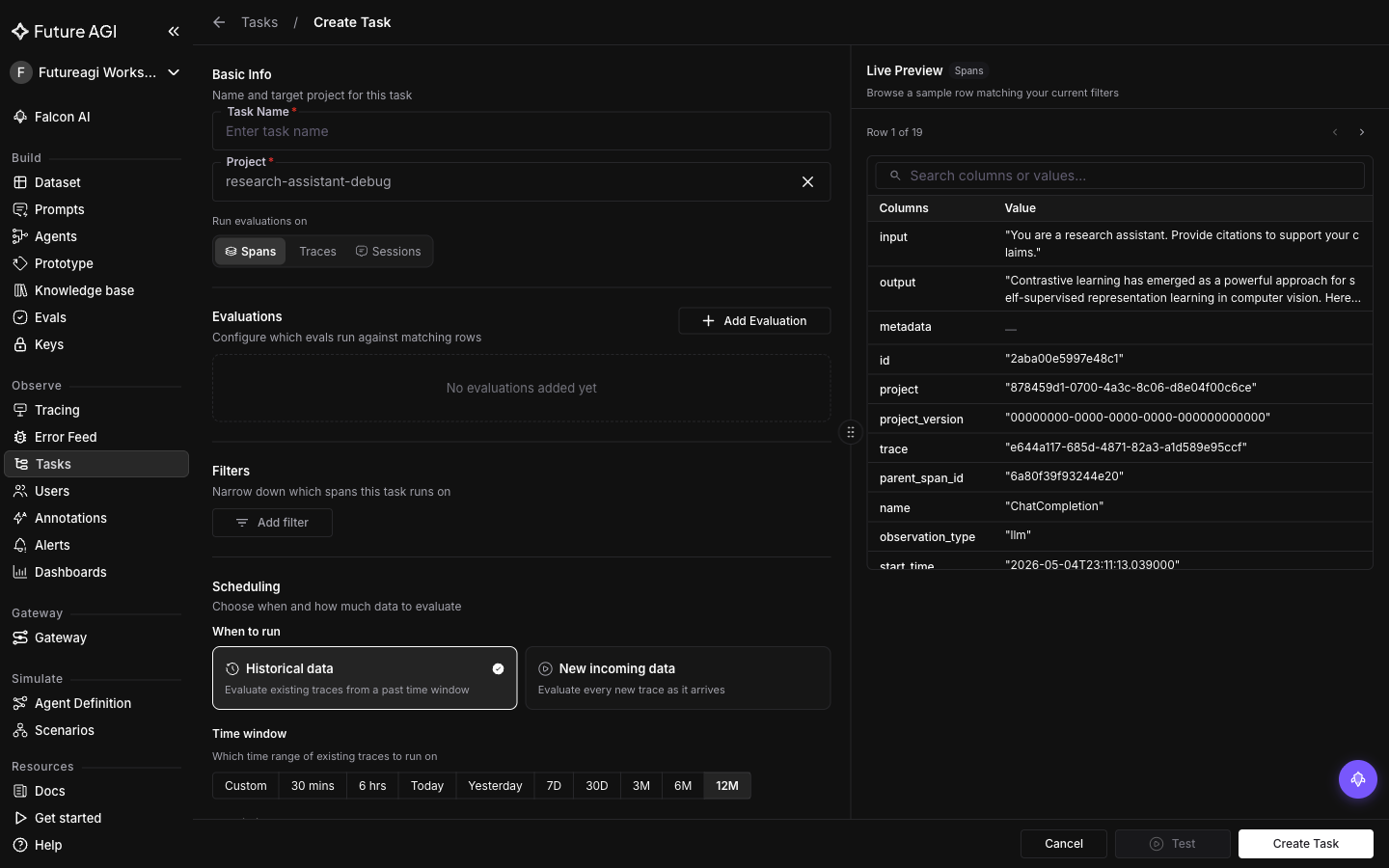 +
+Configure the filters:
+
+| Filter | Recommended value | Why |
+|---|---|---|
+| `observation_type` | `["llm"]` | Only score actual LLM responses, skip tool calls and chains |
+| `span_attributes_filters` | `[{"key": "agent.name", "value": "support_bot", "operator": "equals"}]` | Restrict to the user-facing agent, skip background workers |
+| `date_range` | leave open for continuous tasks | Continuous mode picks up new spans only |
+
+If you're managing tasks programmatically, the same filters go in the eval task's `filters` field on `POST /tracer/eval-task/`. See [Eval task API](#eval-task-api) below.
+
+
+
+
+Sampling cuts cost linearly. A `sampling_rate` of 10 means the task evaluates 10% of matching spans and pays 10% of the tokens.
+
+The right rate depends on traffic volume and how quickly you need to detect a quality drop:
+
+| Daily LLM spans | Sampling rate | Why |
+|---|---|---|
+| < 1,000 | 100% | Volume is low enough that full coverage is cheap |
+| 1,000 to 10,000 | 25 to 50% | Statistically meaningful per-day signal at moderate cost |
+| 10,000 to 100,000 | 10 to 20% | Drop detection within hours, not minutes |
+| > 100,000 | 5 to 10% | Minutes-level detection at high volume needs sampling discipline |
+
+Combine with `spans_limit` as a hard ceiling. For example: `sampling_rate=10` with `spans_limit=5000` means "evaluate 10% of matching spans, but never more than 5,000 per run, no matter how much traffic spikes."
+
+```bash
+# Eval task config (sent to POST /tracer/eval-task/)
+{
+ "project": "",
+ "name": "support-bot-quality-continuous",
+ "evals": ["", ""],
+ "run_type": "continuous",
+ "sampling_rate": 10,
+ "spans_limit": 5000,
+ "filters": {
+ "observation_type": ["llm"],
+ "span_attributes_filters": [
+ {"key": "agent.name", "value": "support_bot", "operator": "equals"}
+ ]
+ }
+}
+```
+
+The defaults (`100%`, `1000` spans) are wrong for production. They exist to make the first run on a small dataset feel responsive, not to scale.
+
+
+
+
+Without alerts you're paying for evals nobody reads. Create an alert monitor on the eval metric so the only time you look at the dashboard is when a quality drop has already crossed your threshold.
+
+In **Observe → Alerts → New Monitor**, configure:
+
+- **Metric**: the `CustomEvalConfig` UUID from the eval task above
+- **Threshold type**: `percentage_change` (catches regressions, not just absolute floors)
+- **Critical threshold**: 15 (a 15% drop in pass rate vs the prior window pages you)
+- **Warning threshold**: 5 (a 5% drop logs to the dashboard but doesn't page)
+- **Alert frequency**: 60 minutes (matches the typical cadence of a sampled continuous task)
+- **Notification emails**: your on-call rotation
+
+```python
+# Same monitor via the API
+import requests, os
+
+requests.post(
+ "https://api.futureagi.com/tracer/user-alerts/",
+ headers={
+ "X-Api-Key": os.environ["FI_API_KEY"],
+ "X-Secret-Key": os.environ["FI_SECRET_KEY"],
+ },
+ json={
+ "name": "support-bot-quality-drop",
+ "metric_type": "evaluation_metrics",
+ "metric": "",
+ "threshold_type": "percentage_change",
+ "threshold_operator": "less_than",
+ "critical_threshold_value": 15,
+ "warning_threshold_value": 5,
+ "alert_frequency": 60,
+ "project": "",
+ "notification_emails": ["oncall@your-company.com"],
+ },
+)
+```
+
+With sampling at 10% and `turing_flash` as the judge, a project doing 50,000 daily LLM spans now pays roughly 5,000 eval calls a day on the cheapest judge tier, with alerts wired up so quality drops actually surface. Compare to the naive setup (100% sampling, `turing_large`) at 50,000 calls on the most expensive judge tier per day. Same regression detection. Roughly 10% of the token spend.
+
+
+
+
+## What you solved
+
+Every production LLM app needs continuous quality coverage, but the naive setup (100% sampling × heaviest judge model × every span) makes evaluation cost a meaningful fraction of total inference cost. The four levers above (sampling, judge model, filters, alert-driven attention) give you the same regression-detection signal at a fraction of the token spend, and the alert monitor turns the eval results into something a human actually reads.
+
+
+Continuous eval task running on your production project, scoped to user-facing LLM spans, sampling at a rate that matches your traffic, scored by the right judge model for the eval, with an alert monitor wired to your on-call rotation. Eval cost capped, regressions still surfaced.
+
+
+- **Eval cost scaling linearly with traffic**: solved by sampling at 5 to 20% of matching spans
+- **Spending heavyweight judge tokens on routine evals**: solved by using `turing_flash` as the default and escalating only with evidence
+- **Wasting tokens on spans that don't need eval coverage**: solved by `observation_type` and span-attribute filters
+- **Eval results piling up in a dashboard nobody reads**: solved by alert monitors with critical/warning thresholds wired to email or PagerDuty
+
+## Eval task API
+
+The dashboard does the same POST under the hood. Endpoint: `POST /tracer/eval-task/` with `X-Api-Key` and `X-Secret-Key` headers. Required fields:
+
+| Field | Type | Notes |
+|---|---|---|
+| `project` | UUID | Observe project to score |
+| `name` | string | Used in the dashboard to find the task later |
+| `evals` | list of UUIDs | One or more `CustomEvalConfig` IDs already attached to the project |
+| `run_type` | `"continuous"` or `"historical"` | `"continuous"` for ongoing, `"historical"` for one-shot |
+| `sampling_rate` | float, 1.0 to 100.0 | Percentage of matching spans to evaluate |
+| `spans_limit` | int, 1 to 1,000,000 | Hard cap per run. Required for `historical`, ignored for `continuous` |
+| `filters` | dict | `observation_type`, `date_range`, `session_id`, `span_attributes_filters` |
+
+Status values: `pending`, `running`, `completed`, `failed`, `paused`, `deleted`. Pause a runaway task with `POST /tracer/eval-task//pause/`.
+
+## Explore further
+
+
+
+ Full reference for the continuous and historical eval task UI
+
+
+ Pick the right judge tier: turing_flash, turing_small, turing_large
+
+
+ Threshold-based alerts on eval metrics with email and PagerDuty
+
+
diff --git a/src/pages/docs/cookbook/optimization/closing-the-loop-prod-failures.mdx b/src/pages/docs/cookbook/optimization/closing-the-loop-prod-failures.mdx
new file mode 100644
index 00000000..f2206ca8
--- /dev/null
+++ b/src/pages/docs/cookbook/optimization/closing-the-loop-prod-failures.mdx
@@ -0,0 +1,227 @@
+---
+title: "Closing the Loop: Turning Production Failures Into Automated Prompt Improvements"
+description: "Pull failing production traces, build a regression dataset, run prompt optimization against the same eval that flagged the failures, and ship the new prompt. The full failure-to-fix loop in one Python script."
+---
+
+
+
+Configure the filters:
+
+| Filter | Recommended value | Why |
+|---|---|---|
+| `observation_type` | `["llm"]` | Only score actual LLM responses, skip tool calls and chains |
+| `span_attributes_filters` | `[{"key": "agent.name", "value": "support_bot", "operator": "equals"}]` | Restrict to the user-facing agent, skip background workers |
+| `date_range` | leave open for continuous tasks | Continuous mode picks up new spans only |
+
+If you're managing tasks programmatically, the same filters go in the eval task's `filters` field on `POST /tracer/eval-task/`. See [Eval task API](#eval-task-api) below.
+
+
+
+
+Sampling cuts cost linearly. A `sampling_rate` of 10 means the task evaluates 10% of matching spans and pays 10% of the tokens.
+
+The right rate depends on traffic volume and how quickly you need to detect a quality drop:
+
+| Daily LLM spans | Sampling rate | Why |
+|---|---|---|
+| < 1,000 | 100% | Volume is low enough that full coverage is cheap |
+| 1,000 to 10,000 | 25 to 50% | Statistically meaningful per-day signal at moderate cost |
+| 10,000 to 100,000 | 10 to 20% | Drop detection within hours, not minutes |
+| > 100,000 | 5 to 10% | Minutes-level detection at high volume needs sampling discipline |
+
+Combine with `spans_limit` as a hard ceiling. For example: `sampling_rate=10` with `spans_limit=5000` means "evaluate 10% of matching spans, but never more than 5,000 per run, no matter how much traffic spikes."
+
+```bash
+# Eval task config (sent to POST /tracer/eval-task/)
+{
+ "project": "",
+ "name": "support-bot-quality-continuous",
+ "evals": ["", ""],
+ "run_type": "continuous",
+ "sampling_rate": 10,
+ "spans_limit": 5000,
+ "filters": {
+ "observation_type": ["llm"],
+ "span_attributes_filters": [
+ {"key": "agent.name", "value": "support_bot", "operator": "equals"}
+ ]
+ }
+}
+```
+
+The defaults (`100%`, `1000` spans) are wrong for production. They exist to make the first run on a small dataset feel responsive, not to scale.
+
+
+
+
+Without alerts you're paying for evals nobody reads. Create an alert monitor on the eval metric so the only time you look at the dashboard is when a quality drop has already crossed your threshold.
+
+In **Observe → Alerts → New Monitor**, configure:
+
+- **Metric**: the `CustomEvalConfig` UUID from the eval task above
+- **Threshold type**: `percentage_change` (catches regressions, not just absolute floors)
+- **Critical threshold**: 15 (a 15% drop in pass rate vs the prior window pages you)
+- **Warning threshold**: 5 (a 5% drop logs to the dashboard but doesn't page)
+- **Alert frequency**: 60 minutes (matches the typical cadence of a sampled continuous task)
+- **Notification emails**: your on-call rotation
+
+```python
+# Same monitor via the API
+import requests, os
+
+requests.post(
+ "https://api.futureagi.com/tracer/user-alerts/",
+ headers={
+ "X-Api-Key": os.environ["FI_API_KEY"],
+ "X-Secret-Key": os.environ["FI_SECRET_KEY"],
+ },
+ json={
+ "name": "support-bot-quality-drop",
+ "metric_type": "evaluation_metrics",
+ "metric": "",
+ "threshold_type": "percentage_change",
+ "threshold_operator": "less_than",
+ "critical_threshold_value": 15,
+ "warning_threshold_value": 5,
+ "alert_frequency": 60,
+ "project": "",
+ "notification_emails": ["oncall@your-company.com"],
+ },
+)
+```
+
+With sampling at 10% and `turing_flash` as the judge, a project doing 50,000 daily LLM spans now pays roughly 5,000 eval calls a day on the cheapest judge tier, with alerts wired up so quality drops actually surface. Compare to the naive setup (100% sampling, `turing_large`) at 50,000 calls on the most expensive judge tier per day. Same regression detection. Roughly 10% of the token spend.
+
+
+
+
+## What you solved
+
+Every production LLM app needs continuous quality coverage, but the naive setup (100% sampling × heaviest judge model × every span) makes evaluation cost a meaningful fraction of total inference cost. The four levers above (sampling, judge model, filters, alert-driven attention) give you the same regression-detection signal at a fraction of the token spend, and the alert monitor turns the eval results into something a human actually reads.
+
+
+Continuous eval task running on your production project, scoped to user-facing LLM spans, sampling at a rate that matches your traffic, scored by the right judge model for the eval, with an alert monitor wired to your on-call rotation. Eval cost capped, regressions still surfaced.
+
+
+- **Eval cost scaling linearly with traffic**: solved by sampling at 5 to 20% of matching spans
+- **Spending heavyweight judge tokens on routine evals**: solved by using `turing_flash` as the default and escalating only with evidence
+- **Wasting tokens on spans that don't need eval coverage**: solved by `observation_type` and span-attribute filters
+- **Eval results piling up in a dashboard nobody reads**: solved by alert monitors with critical/warning thresholds wired to email or PagerDuty
+
+## Eval task API
+
+The dashboard does the same POST under the hood. Endpoint: `POST /tracer/eval-task/` with `X-Api-Key` and `X-Secret-Key` headers. Required fields:
+
+| Field | Type | Notes |
+|---|---|---|
+| `project` | UUID | Observe project to score |
+| `name` | string | Used in the dashboard to find the task later |
+| `evals` | list of UUIDs | One or more `CustomEvalConfig` IDs already attached to the project |
+| `run_type` | `"continuous"` or `"historical"` | `"continuous"` for ongoing, `"historical"` for one-shot |
+| `sampling_rate` | float, 1.0 to 100.0 | Percentage of matching spans to evaluate |
+| `spans_limit` | int, 1 to 1,000,000 | Hard cap per run. Required for `historical`, ignored for `continuous` |
+| `filters` | dict | `observation_type`, `date_range`, `session_id`, `span_attributes_filters` |
+
+Status values: `pending`, `running`, `completed`, `failed`, `paused`, `deleted`. Pause a runaway task with `POST /tracer/eval-task//pause/`.
+
+## Explore further
+
+
+
+ Full reference for the continuous and historical eval task UI
+
+
+ Pick the right judge tier: turing_flash, turing_small, turing_large
+
+
+ Threshold-based alerts on eval metrics with email and PagerDuty
+
+
diff --git a/src/pages/docs/cookbook/optimization/closing-the-loop-prod-failures.mdx b/src/pages/docs/cookbook/optimization/closing-the-loop-prod-failures.mdx
new file mode 100644
index 00000000..f2206ca8
--- /dev/null
+++ b/src/pages/docs/cookbook/optimization/closing-the-loop-prod-failures.mdx
@@ -0,0 +1,227 @@
+---
+title: "Closing the Loop: Turning Production Failures Into Automated Prompt Improvements"
+description: "Pull failing production traces, build a regression dataset, run prompt optimization against the same eval that flagged the failures, and ship the new prompt. The full failure-to-fix loop in one Python script."
+---
+
+
+
+
+
+
+
+
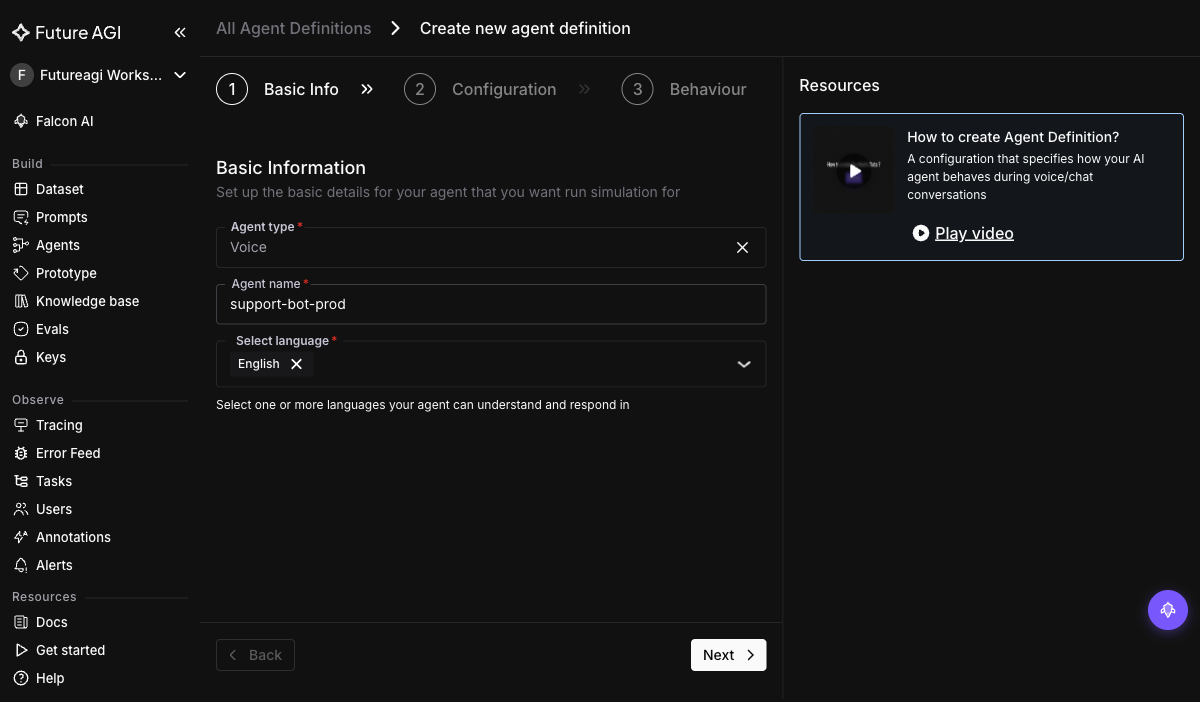 +
+Then fill in the provider connection. Choose `Retell` as the Voice/Chat Provider and paste the API key + Agent ID:
+
+
+
+Then fill in the provider connection. Choose `Retell` as the Voice/Chat Provider and paste the API key + Agent ID:
+
+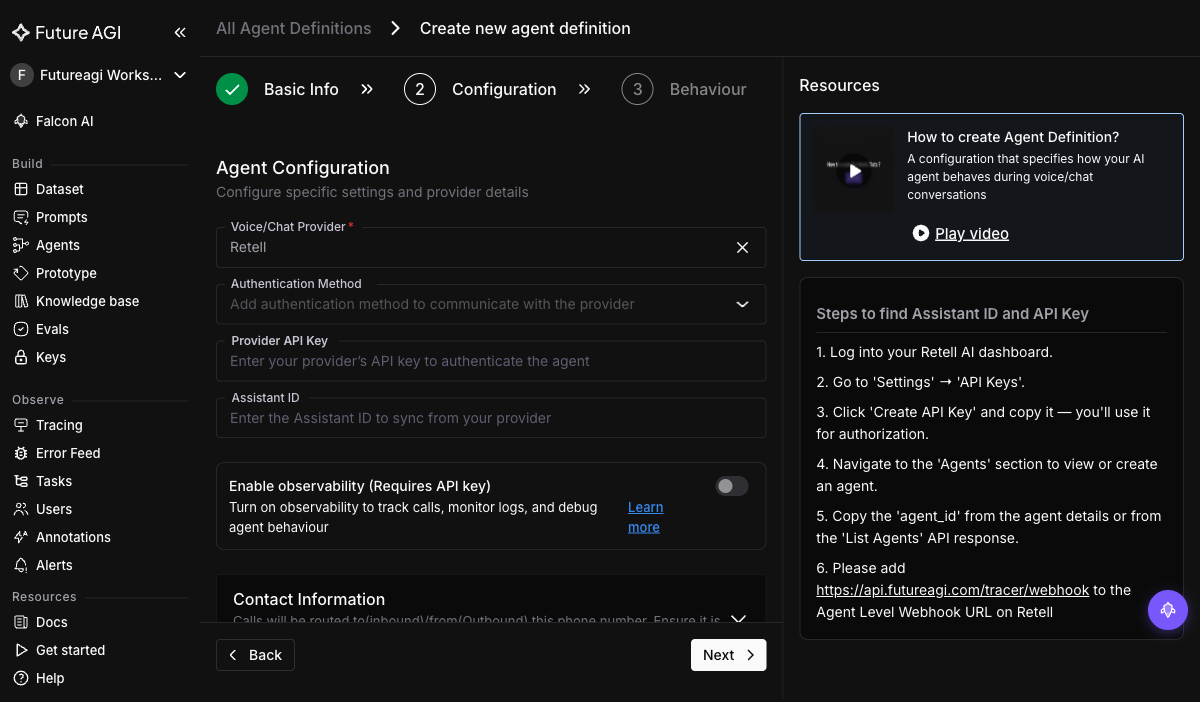 +
+| Field | Value for Retell |
+|---|---|
+| Voice/Chat Provider | `Retell` |
+| API Key | Your Retell API key |
+| Agent ID | The UUID from your Retell dashboard's agent detail page |
+| Phone number | The provisioned number Simulate should dial from (E.164 format) |
+| System prompt | Paste the same prompt you have configured on the Retell side. This is what Fix My Agent will diff against in step 4. |
+
+Save as `retell-prod-v1`. Every later run references this agent definition.
+
+
+
+
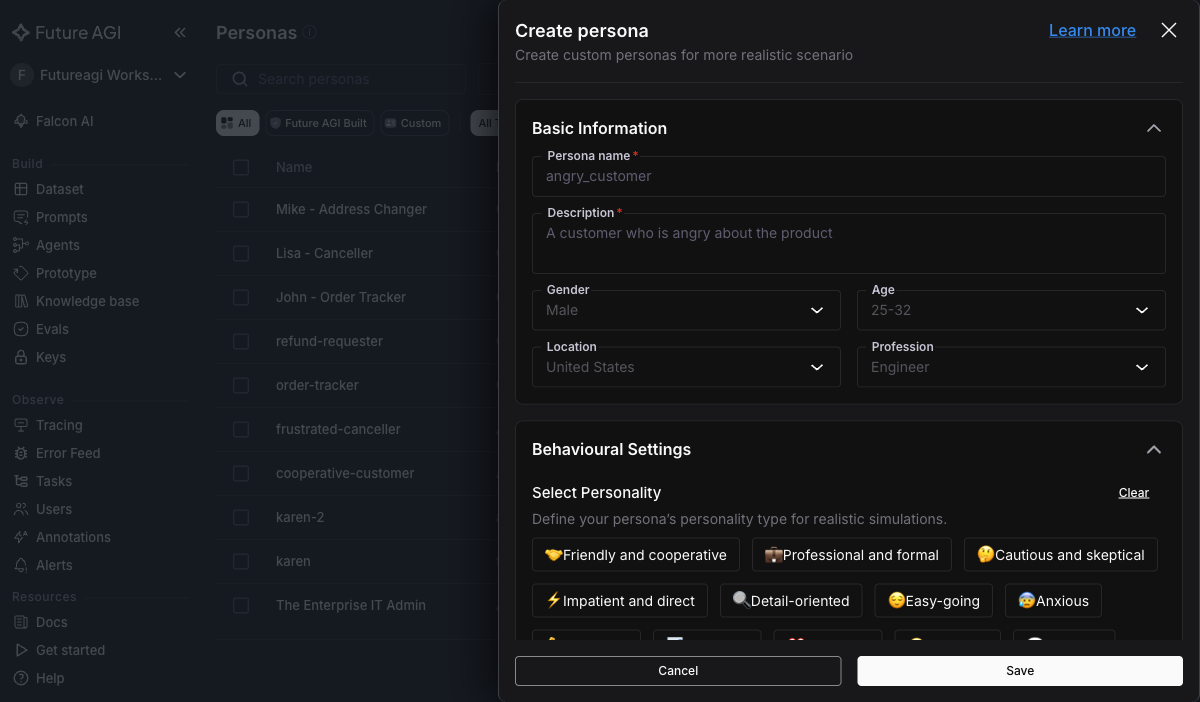
+Personas are the simulated callers. For a Retell support agent you want at least three to cover the conversational pressure points your prompt has to handle. In **Simulate → Personas → Create your own persona**, set type to **Voice** and fill in name, tone, and behavioural settings:
+
+
+
+| Field | Value for Retell |
+|---|---|
+| Voice/Chat Provider | `Retell` |
+| API Key | Your Retell API key |
+| Agent ID | The UUID from your Retell dashboard's agent detail page |
+| Phone number | The provisioned number Simulate should dial from (E.164 format) |
+| System prompt | Paste the same prompt you have configured on the Retell side. This is what Fix My Agent will diff against in step 4. |
+
+Save as `retell-prod-v1`. Every later run references this agent definition.
+
+
+
+
+Personas are the simulated callers. For a Retell support agent you want at least three to cover the conversational pressure points your prompt has to handle. In **Simulate → Personas → Create your own persona**, set type to **Voice** and fill in name, tone, and behavioural settings:
+
+ +
+Create:
+
+- **`cooperative-caller`**: tone neutral, speed moderate, no background noise. Tests the happy path so you have a baseline pass rate.
+- **`frustrated-caller`**: tone irritated, speed fast, light background noise, interrupt sensitivity high. Tests how the agent handles emotional pressure (the most common production failure on phone support).
+- **`accent-mismatch-caller`**: accent mismatched to the STT's training distribution (e.g. Indian English on a US-trained STT). Tests STT robustness, which Retell handles for you but can still trip up on terse replies.
+
+Personas are reusable across agent definitions, so the same library applies to staging or rollback versions of `retell-prod-v1`.
+
+
+
+
+Scenarios bundle a description of the caller's job with concrete conversation paths. In **Simulate → Scenarios → Add scenario**, pick **Workflow Builder** with **Auto Generate Graph**:
+
+
+
+Create:
+
+- **`cooperative-caller`**: tone neutral, speed moderate, no background noise. Tests the happy path so you have a baseline pass rate.
+- **`frustrated-caller`**: tone irritated, speed fast, light background noise, interrupt sensitivity high. Tests how the agent handles emotional pressure (the most common production failure on phone support).
+- **`accent-mismatch-caller`**: accent mismatched to the STT's training distribution (e.g. Indian English on a US-trained STT). Tests STT robustness, which Retell handles for you but can still trip up on terse replies.
+
+Personas are reusable across agent definitions, so the same library applies to staging or rollback versions of `retell-prod-v1`.
+
+
+
+
+Scenarios bundle a description of the caller's job with concrete conversation paths. In **Simulate → Scenarios → Add scenario**, pick **Workflow Builder** with **Auto Generate Graph**:
+
+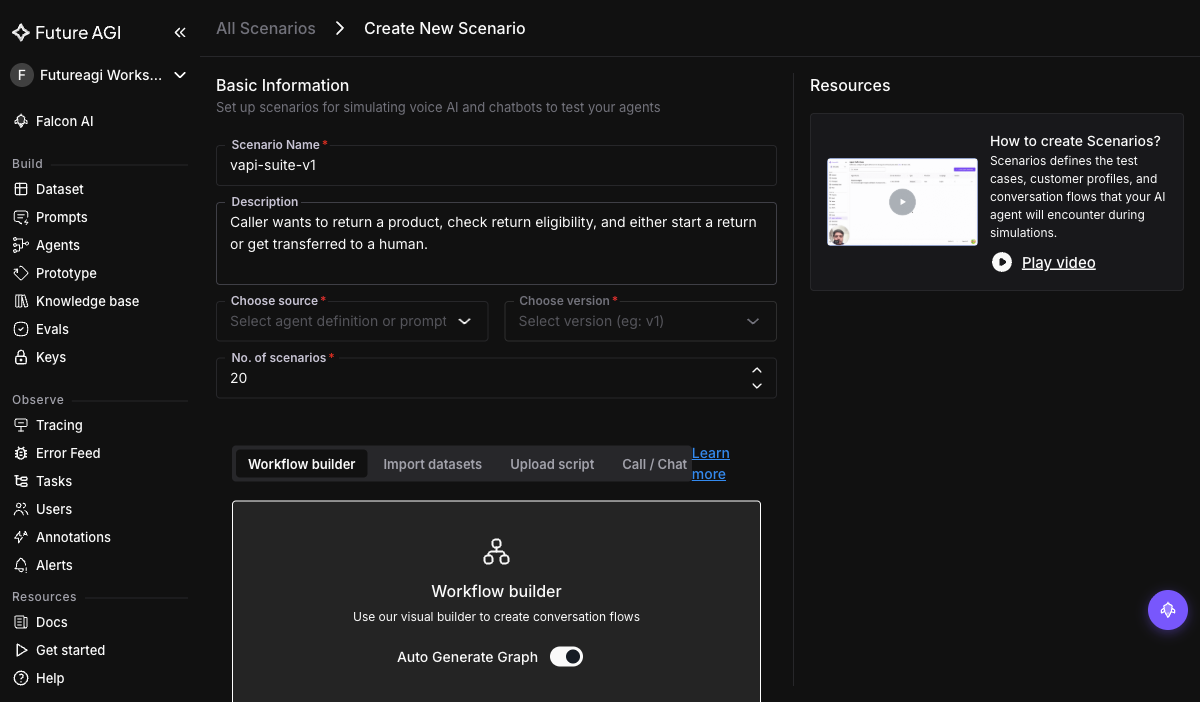 +
+Write one sentence describing what callers do (e.g. *"Caller wants to schedule a service appointment, confirm the time slot, and either book or reschedule"*). The auto-generator builds 20-50 conversation paths covering happy path, edge cases, and adversarial-but-realistic deviations. Save as `retell-suite-v1`.
+
+In **Simulate → Run Simulation**, queue the run with these evals attached:
+
+| Eval | Catches | Recommended judge model |
+|---|---|---|
+| `is_helpful` | Did the agent address what the caller actually asked? | `turing_flash` |
+| `task_completion` | Did the call reach the scenario's expected outcome? | `turing_flash` |
+| `tone` | Was the tone appropriate for a support call? | `turing_flash` |
+
+Each row in the scenario produces one real phone call through your Retell agent. A 30-row scenario takes roughly the time of the longest call (Simulate parallelizes them), and the per-call cost is one Retell minute plus three evaluator calls.
+
+
+
+
+Run results land in **Simulate → Run Tests** with per-call transcripts, recordings, and eval scores:
+
+
+
+Write one sentence describing what callers do (e.g. *"Caller wants to schedule a service appointment, confirm the time slot, and either book or reschedule"*). The auto-generator builds 20-50 conversation paths covering happy path, edge cases, and adversarial-but-realistic deviations. Save as `retell-suite-v1`.
+
+In **Simulate → Run Simulation**, queue the run with these evals attached:
+
+| Eval | Catches | Recommended judge model |
+|---|---|---|
+| `is_helpful` | Did the agent address what the caller actually asked? | `turing_flash` |
+| `task_completion` | Did the call reach the scenario's expected outcome? | `turing_flash` |
+| `tone` | Was the tone appropriate for a support call? | `turing_flash` |
+
+Each row in the scenario produces one real phone call through your Retell agent. A 30-row scenario takes roughly the time of the longest call (Simulate parallelizes them), and the per-call cost is one Retell minute plus three evaluator calls.
+
+
+
+
+Run results land in **Simulate → Run Tests** with per-call transcripts, recordings, and eval scores:
+
+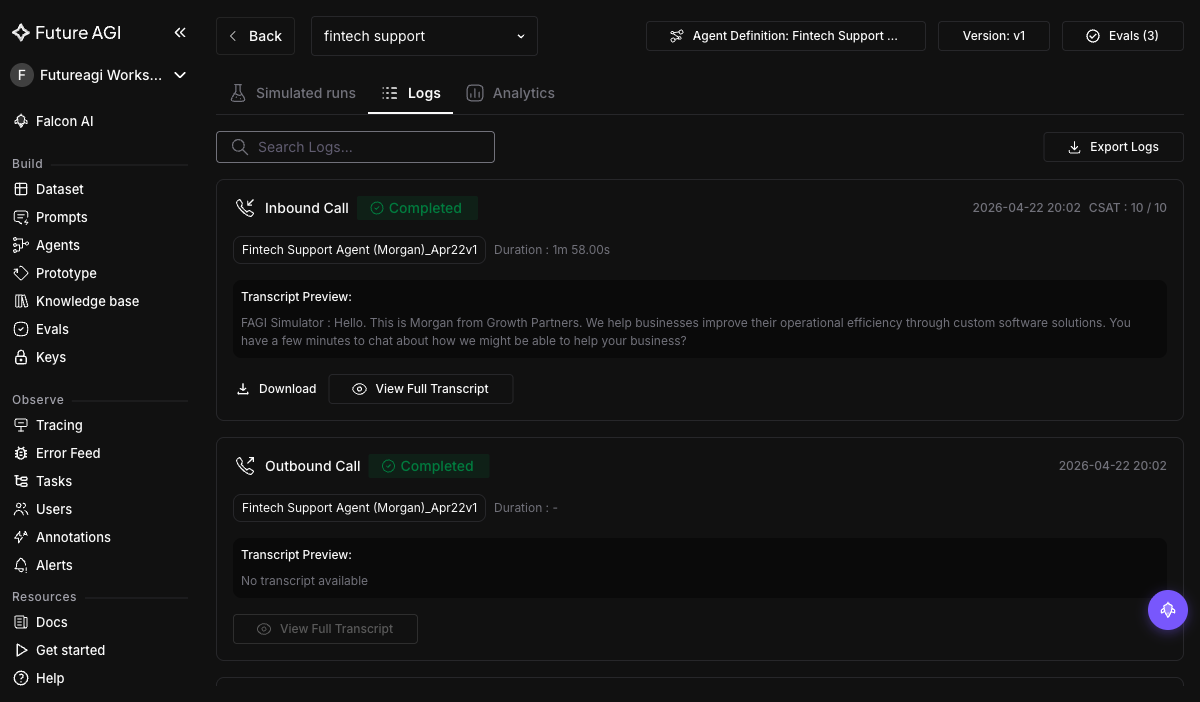 +
+Sort by `task_completion: Failed` to see where the agent gave up or got stuck. Click into one failing call to see the full transcript with eval reasons:
+
+
+
+Sort by `task_completion: Failed` to see where the agent gave up or got stuck. Click into one failing call to see the full transcript with eval reasons:
+
+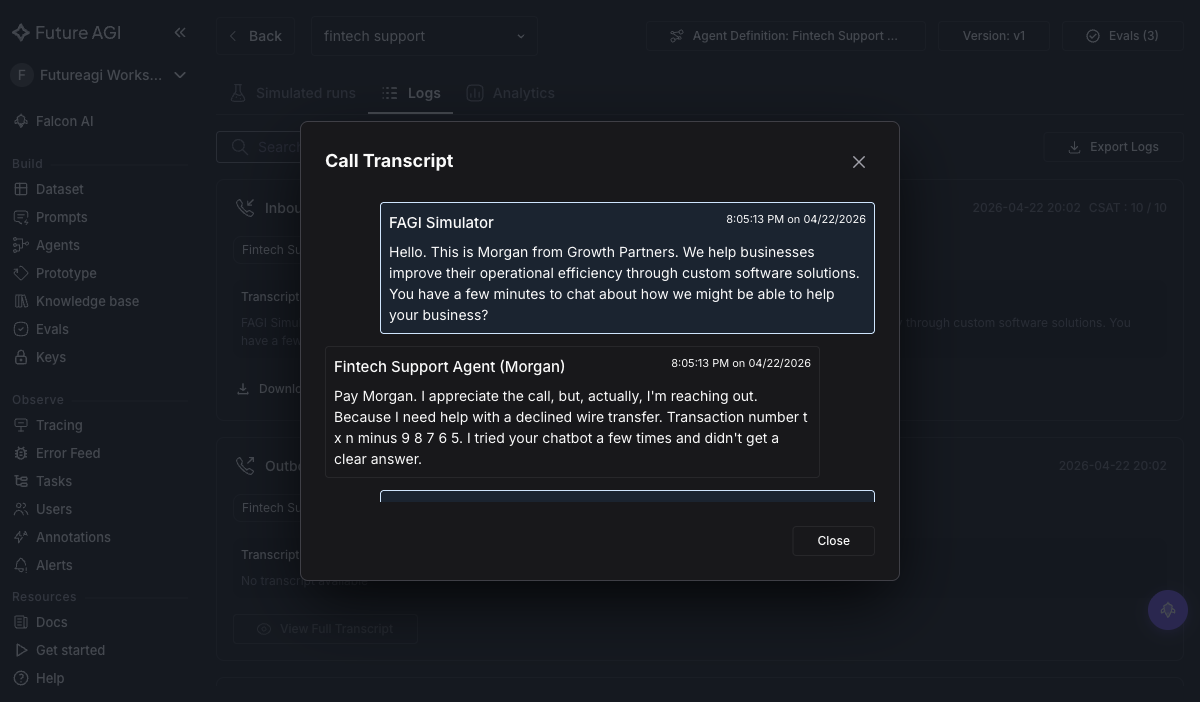 +
+Then run **Fix My Agent**: it reads the transcript, the eval reasons, and the system prompt you saved on the agent definition, then returns a paste-ready prompt diff:
+
+```
+Current:
+You are a helpful scheduling assistant for ServiceCo. Help customers book appointments.
+
+Replace with:
+You are a phone scheduling assistant for ServiceCo. Three rules for every call:
+1. Confirm the exact time slot back to the caller before booking. No assumed dates.
+2. Keep replies under 2 sentences. Long replies feel slow on the phone.
+3. If the caller asks for something outside scheduling, offer to transfer to a human.
+```
+
+Apply the diff to your Retell agent's system prompt, update the matching field on the `retell-prod-v1` agent definition so the next run uses the new prompt, and re-run `retell-suite-v1`. The pass rate on the failing rows should climb. The same suite catches regressions on every future prompt change.
+
+
+
+
+## What you solved
+
+Retell handles the telephony plumbing, but quality regressions on prompt changes still ship to real callers unless something is testing the agent before rollout. One Simulate suite gives you a regression test that places real phone calls through Retell as different personas, scores every conversation automatically, and surfaces a paste-ready prompt diff when something fails. Same suite re-runs on every prompt change so "did this regress?" takes minutes instead of waiting for a user to complain.
+
+
+Retell agent under test, three personas covering happy / frustrated / accent-mismatch paths, one auto-generated scenario with 20-50 conversation paths, three evals scoring helpfulness / completion / tone per call, and Fix My Agent producing a paste-ready prompt diff. Re-runnable on every prompt change.
+
+
+- **No regression test before shipping Retell prompt changes**: solved by the same scenario library running on every prompt update
+- **Adversarial calls discovered only when users complain**: solved by `frustrated-caller` and `accent-mismatch-caller` personas surfacing them in CI
+- **Manual transcript review of failing calls**: solved by `is_helpful`, `task_completion`, and `tone` evals scoring every row automatically
+- **Prompt edits ship without measured impact**: solved by re-running the suite after each change and reading the pass-rate delta
+
+## Explore further
+
+
+
+ Full walkthrough for the Vapi / Retell phone-call flow with screenshots
+
+
+ Mirror of this cookbook for Vapi-hosted assistants
+
+
+ STT / LLM / TTS as independent spans for latency debugging
+
+
diff --git a/src/pages/docs/cookbook/voice/simulate-vapi.mdx b/src/pages/docs/cookbook/voice/simulate-vapi.mdx
new file mode 100644
index 00000000..e2fbdf0e
--- /dev/null
+++ b/src/pages/docs/cookbook/voice/simulate-vapi.mdx
@@ -0,0 +1,133 @@
+---
+title: "How to Test, Evaluate, and Improve Vapi Voice Agents With Future AGI Simulate"
+description: "Build personas, scenarios, and evals against a Vapi assistant from the Future AGI dashboard. The same suite re-runs on every prompt change so quality regressions surface before users hear them."
+---
+
+| Time | Difficulty | Package |
+|------|-----------|---------|
+| 20 min | Intermediate | Platform UI |
+
+By the end of this cookbook you will have a Future AGI Simulate suite (three voice personas, one auto-generated scenario, three runtime evals) testing a Vapi assistant by placing real phone calls through your provisioned number, per-call transcripts and eval scores in the dashboard, and a Fix My Agent prompt diff for whichever rows the assistant got wrong.
+
+
+- FutureAGI account → [app.futureagi.com](https://app.futureagi.com)
+- API keys: `FI_API_KEY` and `FI_SECRET_KEY` (see [Get your API keys](/docs/admin-settings))
+- A Vapi account with: an assistant ID, a provisioned phone number, and a Vapi API key
+
+
+## Why simulate a Vapi assistant?
+
+Vapi gives you a hosted phone agent in minutes: paste a system prompt, pick voices, get a number. What it doesn't give you is a regression suite. The first time your support team finds out the new prompt mishandles frustrated callers is in production, by which point real customers have already heard it. Future AGI Simulate places real phone calls through Vapi as different personas, scores the resulting conversations with built-in evals, and re-runs the same suite on every prompt change so the regression surfaces before the rollout.
+
+The four steps below connect Simulate to your Vapi assistant, define the personas and scenario, attach evals, and read the results.
+
+
+
+
+Simulate needs three Vapi-side identifiers to place calls: the assistant ID (which Vapi config to call), the phone number (where calls originate from), and the API key (auth). In **Simulate → Agent Definition → Create agent definition**, start with the basic info:
+
+
+
+Then run **Fix My Agent**: it reads the transcript, the eval reasons, and the system prompt you saved on the agent definition, then returns a paste-ready prompt diff:
+
+```
+Current:
+You are a helpful scheduling assistant for ServiceCo. Help customers book appointments.
+
+Replace with:
+You are a phone scheduling assistant for ServiceCo. Three rules for every call:
+1. Confirm the exact time slot back to the caller before booking. No assumed dates.
+2. Keep replies under 2 sentences. Long replies feel slow on the phone.
+3. If the caller asks for something outside scheduling, offer to transfer to a human.
+```
+
+Apply the diff to your Retell agent's system prompt, update the matching field on the `retell-prod-v1` agent definition so the next run uses the new prompt, and re-run `retell-suite-v1`. The pass rate on the failing rows should climb. The same suite catches regressions on every future prompt change.
+
+
+
+
+## What you solved
+
+Retell handles the telephony plumbing, but quality regressions on prompt changes still ship to real callers unless something is testing the agent before rollout. One Simulate suite gives you a regression test that places real phone calls through Retell as different personas, scores every conversation automatically, and surfaces a paste-ready prompt diff when something fails. Same suite re-runs on every prompt change so "did this regress?" takes minutes instead of waiting for a user to complain.
+
+
+Retell agent under test, three personas covering happy / frustrated / accent-mismatch paths, one auto-generated scenario with 20-50 conversation paths, three evals scoring helpfulness / completion / tone per call, and Fix My Agent producing a paste-ready prompt diff. Re-runnable on every prompt change.
+
+
+- **No regression test before shipping Retell prompt changes**: solved by the same scenario library running on every prompt update
+- **Adversarial calls discovered only when users complain**: solved by `frustrated-caller` and `accent-mismatch-caller` personas surfacing them in CI
+- **Manual transcript review of failing calls**: solved by `is_helpful`, `task_completion`, and `tone` evals scoring every row automatically
+- **Prompt edits ship without measured impact**: solved by re-running the suite after each change and reading the pass-rate delta
+
+## Explore further
+
+
+
+ Full walkthrough for the Vapi / Retell phone-call flow with screenshots
+
+
+ Mirror of this cookbook for Vapi-hosted assistants
+
+
+ STT / LLM / TTS as independent spans for latency debugging
+
+
diff --git a/src/pages/docs/cookbook/voice/simulate-vapi.mdx b/src/pages/docs/cookbook/voice/simulate-vapi.mdx
new file mode 100644
index 00000000..e2fbdf0e
--- /dev/null
+++ b/src/pages/docs/cookbook/voice/simulate-vapi.mdx
@@ -0,0 +1,133 @@
+---
+title: "How to Test, Evaluate, and Improve Vapi Voice Agents With Future AGI Simulate"
+description: "Build personas, scenarios, and evals against a Vapi assistant from the Future AGI dashboard. The same suite re-runs on every prompt change so quality regressions surface before users hear them."
+---
+
+| Time | Difficulty | Package |
+|------|-----------|---------|
+| 20 min | Intermediate | Platform UI |
+
+By the end of this cookbook you will have a Future AGI Simulate suite (three voice personas, one auto-generated scenario, three runtime evals) testing a Vapi assistant by placing real phone calls through your provisioned number, per-call transcripts and eval scores in the dashboard, and a Fix My Agent prompt diff for whichever rows the assistant got wrong.
+
+
+- FutureAGI account → [app.futureagi.com](https://app.futureagi.com)
+- API keys: `FI_API_KEY` and `FI_SECRET_KEY` (see [Get your API keys](/docs/admin-settings))
+- A Vapi account with: an assistant ID, a provisioned phone number, and a Vapi API key
+
+
+## Why simulate a Vapi assistant?
+
+Vapi gives you a hosted phone agent in minutes: paste a system prompt, pick voices, get a number. What it doesn't give you is a regression suite. The first time your support team finds out the new prompt mishandles frustrated callers is in production, by which point real customers have already heard it. Future AGI Simulate places real phone calls through Vapi as different personas, scores the resulting conversations with built-in evals, and re-runs the same suite on every prompt change so the regression surfaces before the rollout.
+
+The four steps below connect Simulate to your Vapi assistant, define the personas and scenario, attach evals, and read the results.
+
+
+
+
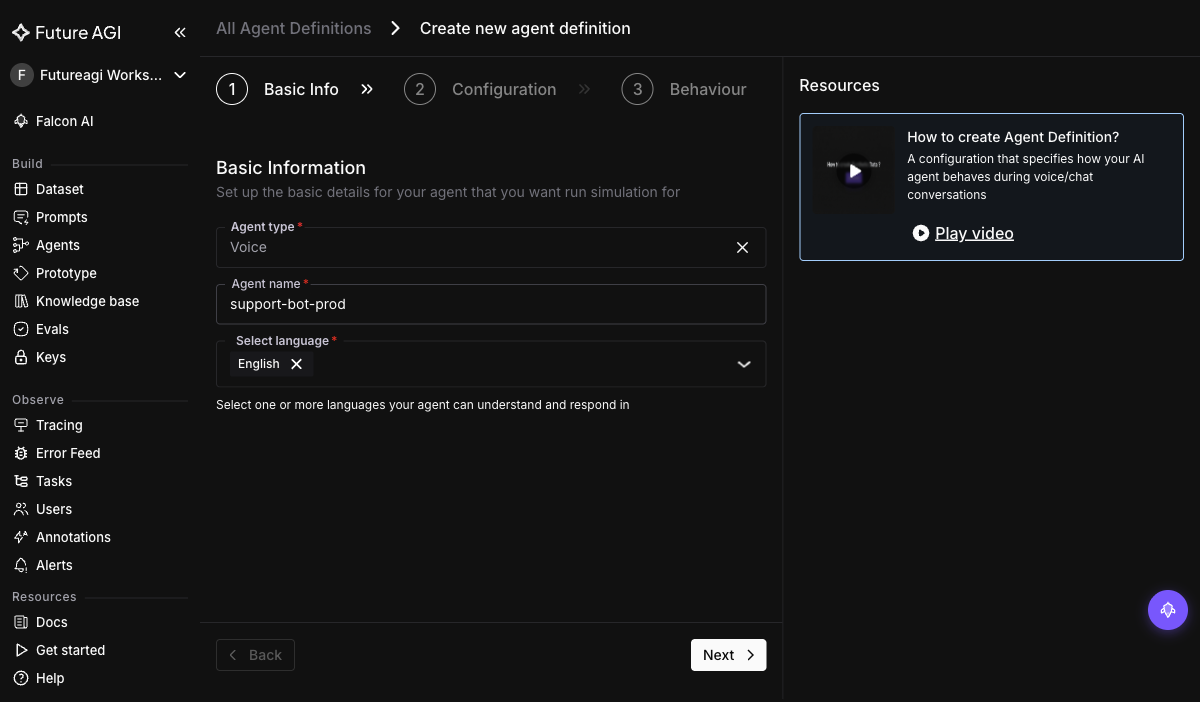
+Simulate needs three Vapi-side identifiers to place calls: the assistant ID (which Vapi config to call), the phone number (where calls originate from), and the API key (auth). In **Simulate → Agent Definition → Create agent definition**, start with the basic info:
+
+ +
+Then fill in the provider connection. Choose `Vapi` as the Voice/Chat Provider and paste the API key + Assistant ID:
+
+
+
+Then fill in the provider connection. Choose `Vapi` as the Voice/Chat Provider and paste the API key + Assistant ID:
+
+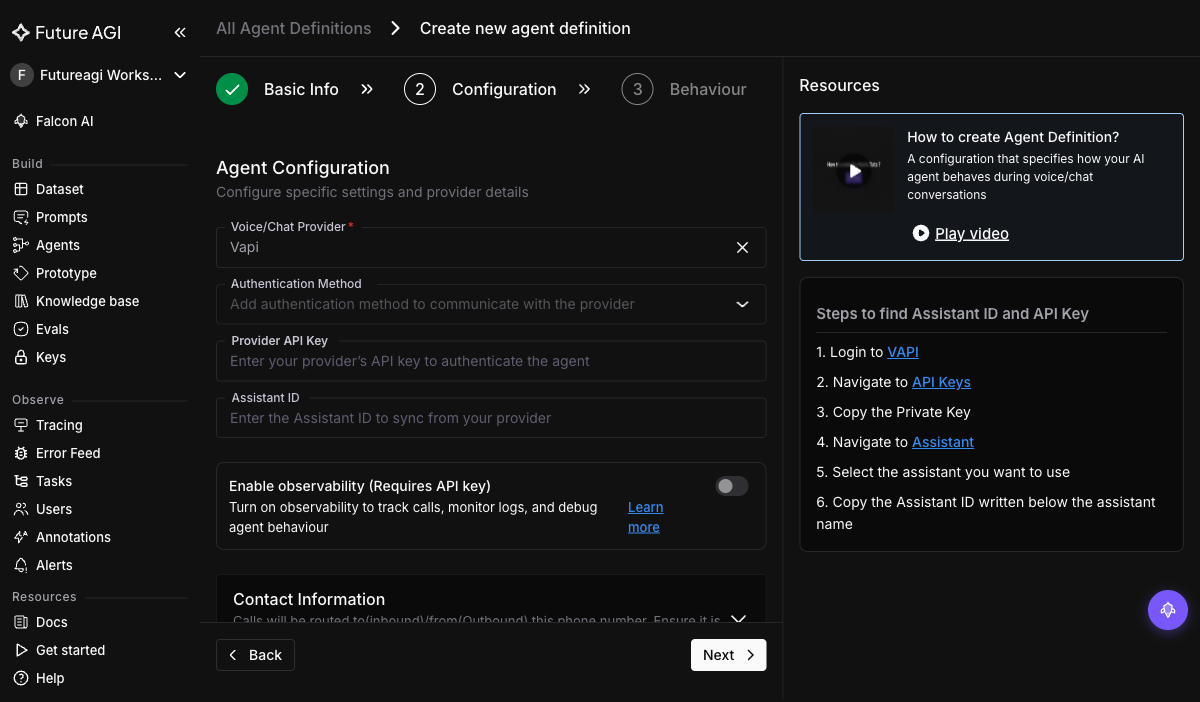 +
+| Field | Value for Vapi |
+|---|---|
+| Voice/Chat Provider | `Vapi` |
+| API Key | Your Vapi API key |
+| Assistant ID | The UUID from your Vapi dashboard's assistant detail page |
+| Phone number | The provisioned number Simulate should dial from (E.164 format) |
+| System prompt | Paste the same prompt you have configured on the Vapi side. This is what Fix My Agent will diff against in step 4. |
+
+Save as `vapi-prod-v1`. Every later run references this agent definition.
+
+
+
+
+Personas are the simulated callers. For a Vapi support agent you want at least three to cover the conversational pressure points your prompt has to handle. In **Simulate → Personas → Create your own persona**, set type to **Voice** and fill in name, tone, and behavioural settings:
+
+
+
+| Field | Value for Vapi |
+|---|---|
+| Voice/Chat Provider | `Vapi` |
+| API Key | Your Vapi API key |
+| Assistant ID | The UUID from your Vapi dashboard's assistant detail page |
+| Phone number | The provisioned number Simulate should dial from (E.164 format) |
+| System prompt | Paste the same prompt you have configured on the Vapi side. This is what Fix My Agent will diff against in step 4. |
+
+Save as `vapi-prod-v1`. Every later run references this agent definition.
+
+
+
+
+Personas are the simulated callers. For a Vapi support agent you want at least three to cover the conversational pressure points your prompt has to handle. In **Simulate → Personas → Create your own persona**, set type to **Voice** and fill in name, tone, and behavioural settings:
+
+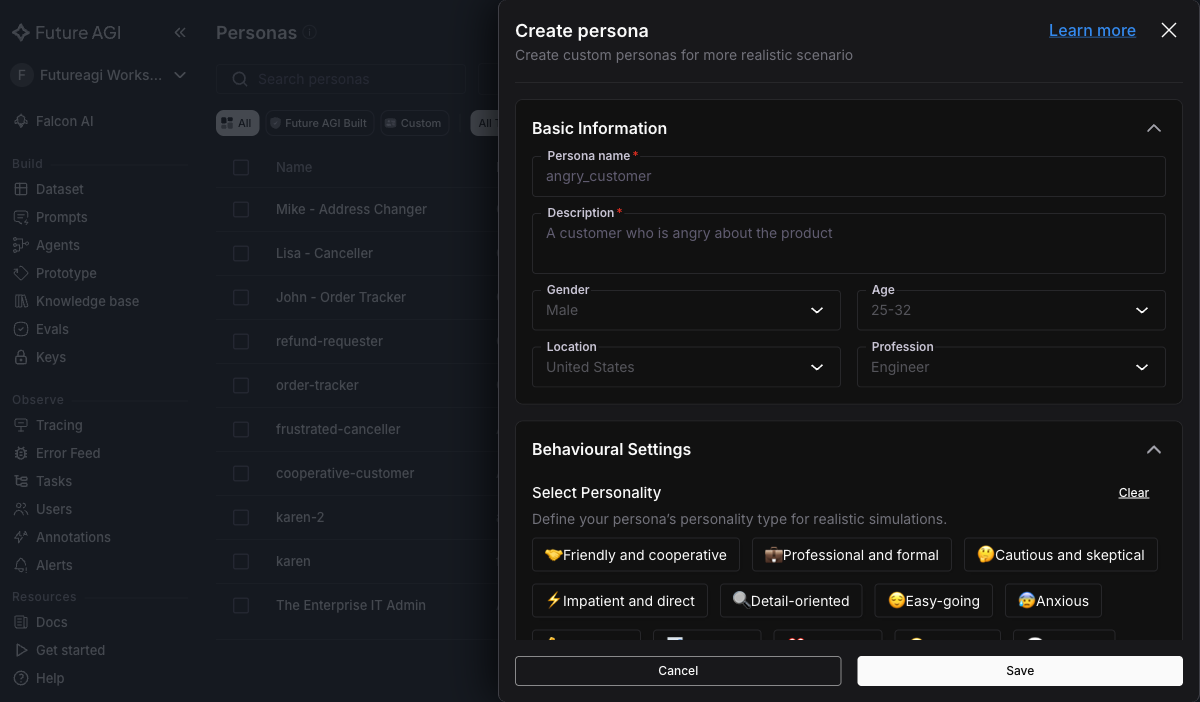 +
+Create:
+
+- **`cooperative-caller`**: tone neutral, speed moderate, no background noise. Tests the happy path so you have a baseline pass rate.
+- **`frustrated-caller`**: tone irritated, speed fast, light background noise, interrupt sensitivity high. Tests how the agent handles emotional pressure (the most common production failure on phone support).
+- **`accent-mismatch-caller`**: accent mismatched to the STT's training distribution (e.g. Indian English on a US-trained STT). Tests STT robustness, which Vapi handles for you but can still trip up on terse replies.
+
+Personas are reusable across agent definitions, so the same library applies to staging or rollback versions of `vapi-prod-v1`.
+
+
+
+
+Scenarios bundle a description of the caller's job with concrete conversation paths. In **Simulate → Scenarios → Add scenario**, pick **Workflow Builder** with **Auto Generate Graph**:
+
+
+
+Create:
+
+- **`cooperative-caller`**: tone neutral, speed moderate, no background noise. Tests the happy path so you have a baseline pass rate.
+- **`frustrated-caller`**: tone irritated, speed fast, light background noise, interrupt sensitivity high. Tests how the agent handles emotional pressure (the most common production failure on phone support).
+- **`accent-mismatch-caller`**: accent mismatched to the STT's training distribution (e.g. Indian English on a US-trained STT). Tests STT robustness, which Vapi handles for you but can still trip up on terse replies.
+
+Personas are reusable across agent definitions, so the same library applies to staging or rollback versions of `vapi-prod-v1`.
+
+
+
+
+Scenarios bundle a description of the caller's job with concrete conversation paths. In **Simulate → Scenarios → Add scenario**, pick **Workflow Builder** with **Auto Generate Graph**:
+
+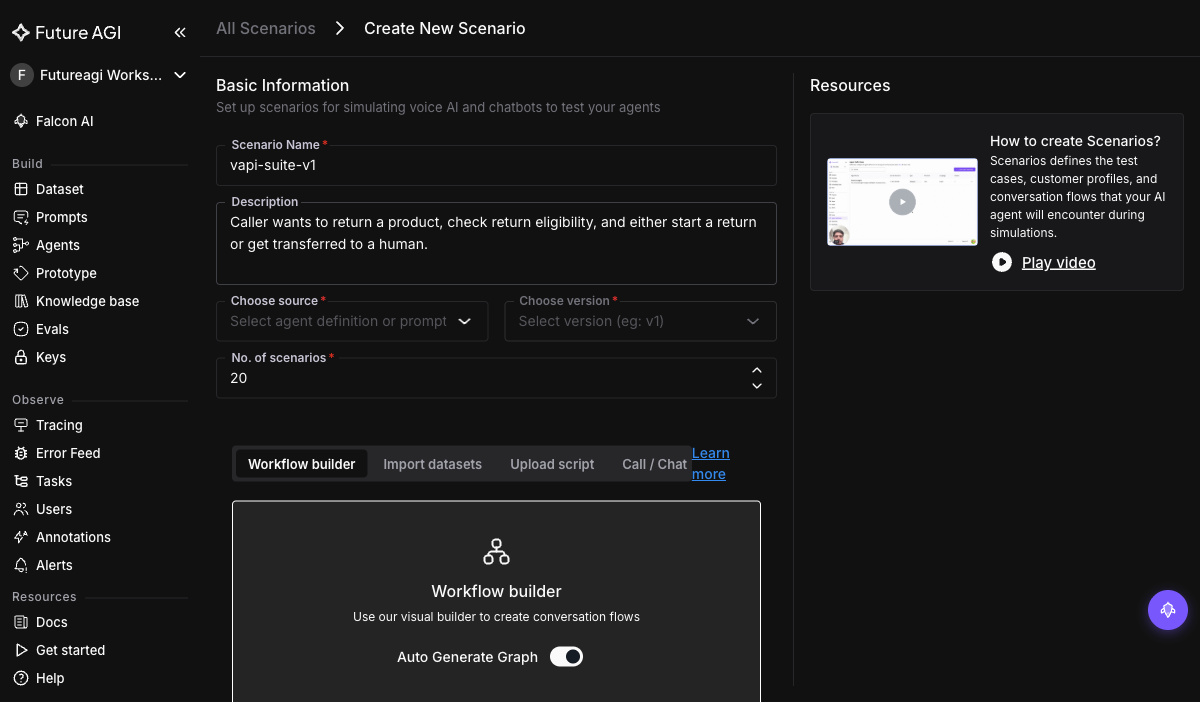 +
+Write one sentence describing what callers do (e.g. *"Caller wants to return a product, check eligibility, and either start the return or get transferred to a human"*). The auto-generator builds 20-50 conversation paths covering happy path, edge cases, and adversarial-but-realistic deviations. Save as `vapi-suite-v1`.
+
+In **Simulate → Run Simulation**, queue the run with these evals attached:
+
+| Eval | Catches | Recommended judge model |
+|---|---|---|
+| `is_helpful` | Did the agent address what the caller actually asked? | `turing_flash` |
+| `task_completion` | Did the call reach the scenario's expected outcome? | `turing_flash` |
+| `tone` | Was the tone appropriate for a support call? | `turing_flash` |
+
+Each row in the scenario produces one real phone call through your Vapi assistant. A 30-row scenario takes roughly the time of the longest call (Simulate parallelizes them), and the per-call cost is one Vapi minute plus three evaluator calls.
+
+
+
+
+Run results land in **Simulate → Run Tests** with per-call transcripts, recordings, and eval scores:
+
+
+
+Write one sentence describing what callers do (e.g. *"Caller wants to return a product, check eligibility, and either start the return or get transferred to a human"*). The auto-generator builds 20-50 conversation paths covering happy path, edge cases, and adversarial-but-realistic deviations. Save as `vapi-suite-v1`.
+
+In **Simulate → Run Simulation**, queue the run with these evals attached:
+
+| Eval | Catches | Recommended judge model |
+|---|---|---|
+| `is_helpful` | Did the agent address what the caller actually asked? | `turing_flash` |
+| `task_completion` | Did the call reach the scenario's expected outcome? | `turing_flash` |
+| `tone` | Was the tone appropriate for a support call? | `turing_flash` |
+
+Each row in the scenario produces one real phone call through your Vapi assistant. A 30-row scenario takes roughly the time of the longest call (Simulate parallelizes them), and the per-call cost is one Vapi minute plus three evaluator calls.
+
+
+
+
+Run results land in **Simulate → Run Tests** with per-call transcripts, recordings, and eval scores:
+
+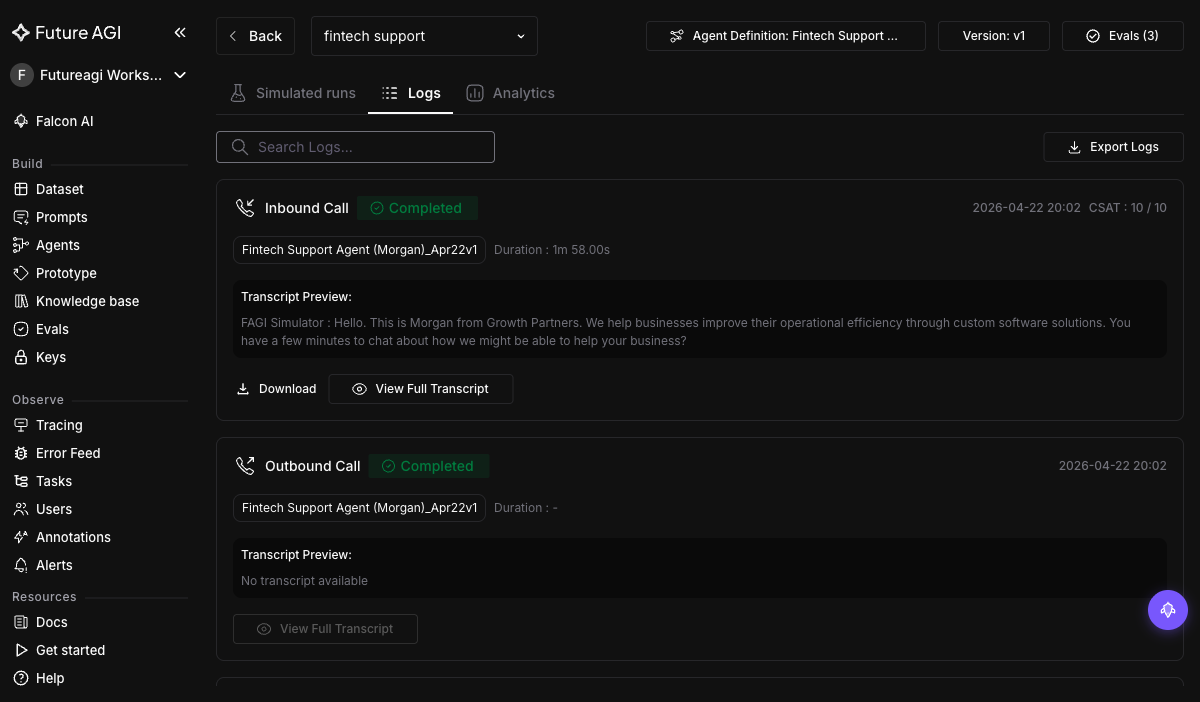 +
+Sort by `task_completion: Failed` to see where the agent gave up or got stuck. Click into one failing call to see the full transcript with eval reasons:
+
+
+
+Sort by `task_completion: Failed` to see where the agent gave up or got stuck. Click into one failing call to see the full transcript with eval reasons:
+
+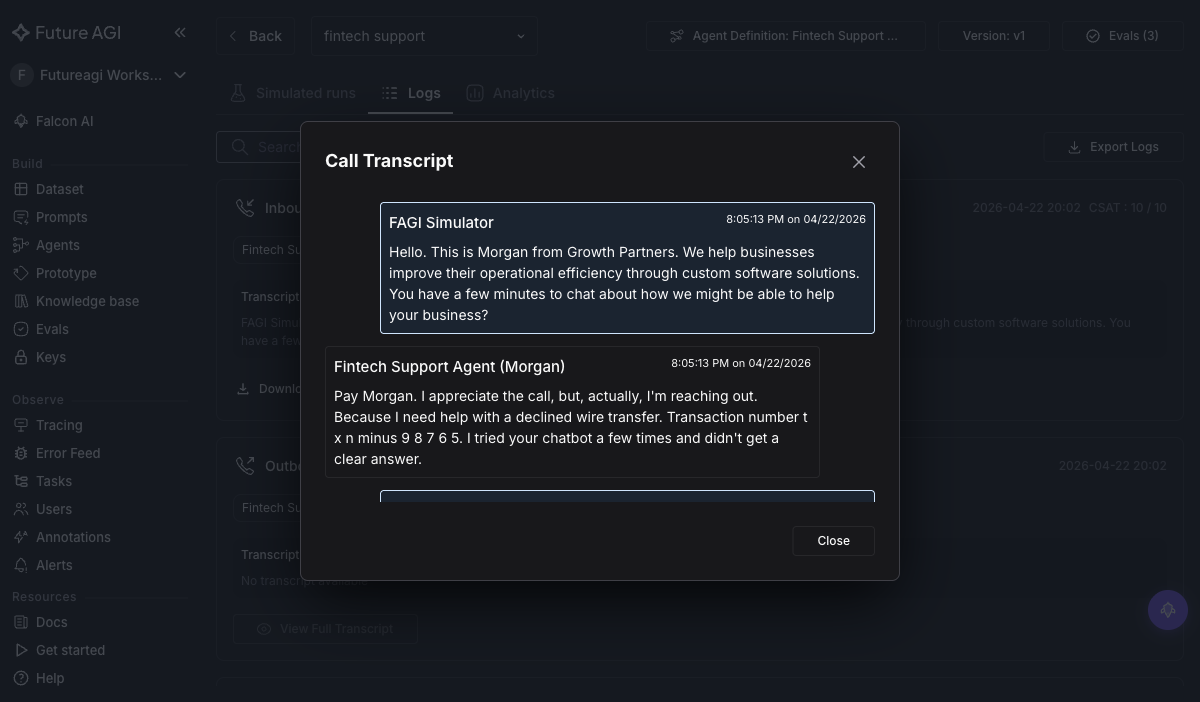 +
+Then run **Fix My Agent**: it reads the transcript, the eval reasons, and the system prompt you saved on the agent definition, then returns a paste-ready prompt diff:
+
+```
+Current:
+You are a helpful support agent for TechStore. Help customers with their issues.
+
+Replace with:
+You are a phone support agent for TechStore. Three rules for every call:
+1. Acknowledge what the caller asked before answering. They can't see a typing indicator.
+2. Keep replies under 2 sentences. Long replies feel slow on the phone.
+3. If you can't resolve in 60 seconds, offer to transfer.
+```
+
+Apply the diff to your Vapi assistant's system prompt, update the matching field on the `vapi-prod-v1` agent definition so the next run uses the new prompt, and re-run `vapi-suite-v1`. The pass rate on the failing rows should climb. The same suite catches regressions on every future prompt change.
+
+
+
+
+## What you solved
+
+Vapi makes spinning up a phone agent easy, but the moment you ship a prompt change you're flying blind on whether you've broken anything. One Simulate suite gives you a regression test that places real phone calls through Vapi as different personas, scores every conversation automatically, and surfaces a paste-ready prompt diff when something fails. Same suite re-runs on every prompt change so the answer to "did this regress?" takes minutes instead of waiting for a user to complain.
+
+
+Vapi assistant under test, three personas covering happy / frustrated / accent-mismatch paths, one auto-generated scenario with 20-50 conversation paths, three evals scoring helpfulness / completion / tone per call, and Fix My Agent producing a paste-ready prompt diff. Re-runnable on every prompt change.
+
+
+- **No regression test before shipping Vapi prompt changes**: solved by the same scenario library running on every prompt update
+- **Adversarial calls discovered only when users complain**: solved by `frustrated-caller` and `accent-mismatch-caller` personas surfacing them in CI
+- **Manual transcript review of failing calls**: solved by `is_helpful`, `task_completion`, and `tone` evals scoring every row automatically
+- **Prompt edits ship without measured impact**: solved by re-running the suite after each change and reading the pass-rate delta
+
+## Explore further
+
+
+
+ Full walkthrough for the Vapi / Retell phone-call flow with screenshots
+
+
+ Mirror of this cookbook for Retell-hosted assistants
+
+
+ STT / LLM / TTS as independent spans for latency debugging
+
+
+
+Then run **Fix My Agent**: it reads the transcript, the eval reasons, and the system prompt you saved on the agent definition, then returns a paste-ready prompt diff:
+
+```
+Current:
+You are a helpful support agent for TechStore. Help customers with their issues.
+
+Replace with:
+You are a phone support agent for TechStore. Three rules for every call:
+1. Acknowledge what the caller asked before answering. They can't see a typing indicator.
+2. Keep replies under 2 sentences. Long replies feel slow on the phone.
+3. If you can't resolve in 60 seconds, offer to transfer.
+```
+
+Apply the diff to your Vapi assistant's system prompt, update the matching field on the `vapi-prod-v1` agent definition so the next run uses the new prompt, and re-run `vapi-suite-v1`. The pass rate on the failing rows should climb. The same suite catches regressions on every future prompt change.
+
+
+
+
+## What you solved
+
+Vapi makes spinning up a phone agent easy, but the moment you ship a prompt change you're flying blind on whether you've broken anything. One Simulate suite gives you a regression test that places real phone calls through Vapi as different personas, scores every conversation automatically, and surfaces a paste-ready prompt diff when something fails. Same suite re-runs on every prompt change so the answer to "did this regress?" takes minutes instead of waiting for a user to complain.
+
+
+Vapi assistant under test, three personas covering happy / frustrated / accent-mismatch paths, one auto-generated scenario with 20-50 conversation paths, three evals scoring helpfulness / completion / tone per call, and Fix My Agent producing a paste-ready prompt diff. Re-runnable on every prompt change.
+
+
+- **No regression test before shipping Vapi prompt changes**: solved by the same scenario library running on every prompt update
+- **Adversarial calls discovered only when users complain**: solved by `frustrated-caller` and `accent-mismatch-caller` personas surfacing them in CI
+- **Manual transcript review of failing calls**: solved by `is_helpful`, `task_completion`, and `tone` evals scoring every row automatically
+- **Prompt edits ship without measured impact**: solved by re-running the suite after each change and reading the pass-rate delta
+
+## Explore further
+
+
+
+ Full walkthrough for the Vapi / Retell phone-call flow with screenshots
+
+
+ Mirror of this cookbook for Retell-hosted assistants
+
+
+ STT / LLM / TTS as independent spans for latency debugging
+
+
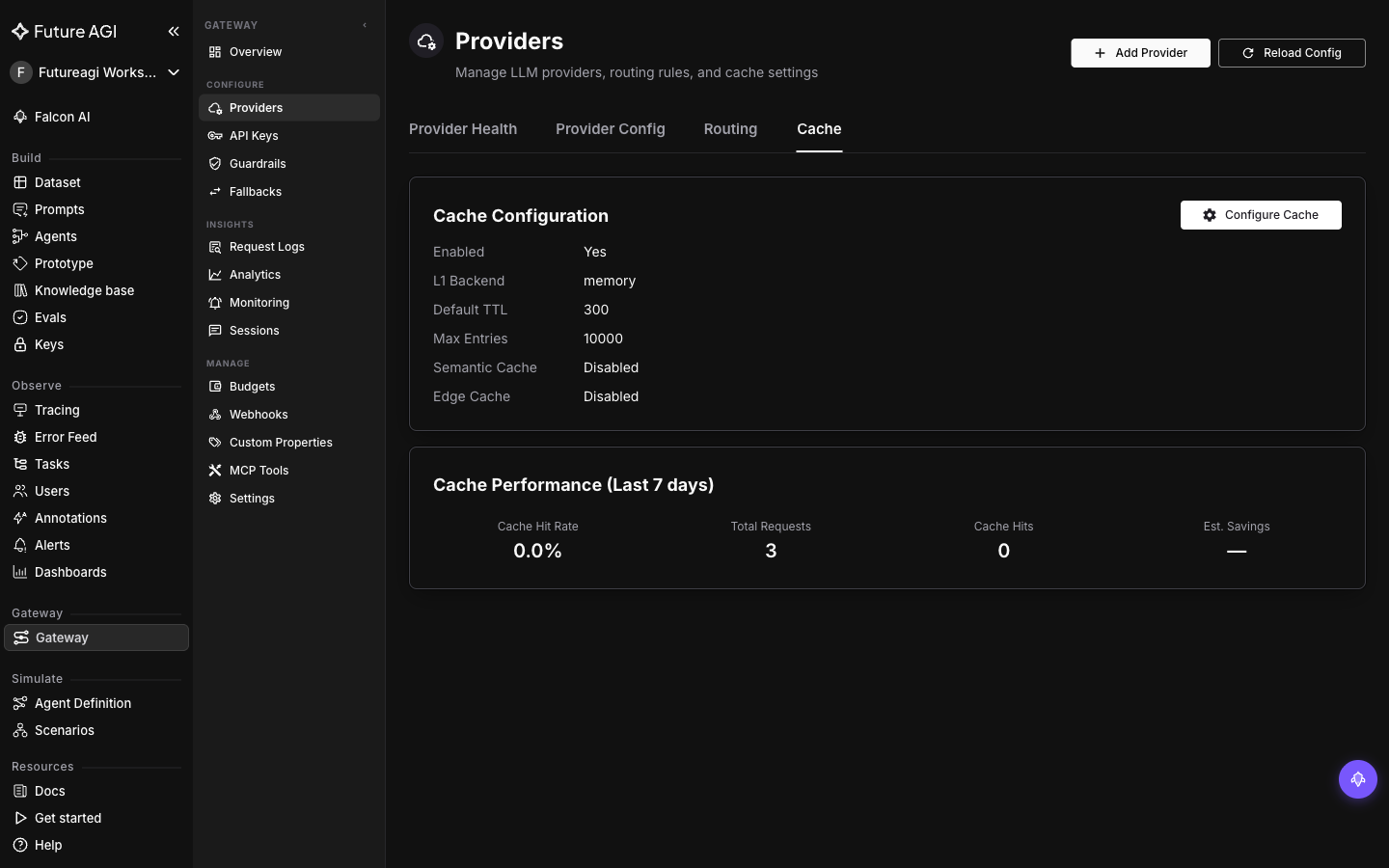 @@ -95,12 +99,12 @@ Use cache **namespaces** to isolate environments or experiments. Set `x-agentcc-
@@ -95,12 +99,12 @@ Use cache **namespaces** to isolate environments or experiments. Set `x-agentcc-