

@@ -14,7 +31,21 @@ Enable caching once in the Agent Command Center dashboard, switch the strategy t
| Time | Difficulty | Package |
|------|-----------|---------|
-| 10 min | Beginner | `agentcc` |
+| 10 min | Beginner | `openai` |
+
+
+Enable exact and semantic response caching at the Agent Command Center gateway so paraphrased duplicate prompts return cached answers instead of hitting your LLM provider again. You'll measure the cost and latency difference on a realistic batch, then learn how to bypass or invalidate the cache when you ship prompt changes. The only code change is pointing your OpenAI SDK at the gateway base URL.
+
+
+## What you'll build
+
+A working caching layer in front of one OpenAI model, configured in the Agent Command Center dashboard and verified from a Python script. By the end you will have:
+
+- A baseline measurement of cost and latency for one uncached request, read directly from `x-agentcc-cost` and `x-agentcc-latency-ms` headers.
+- L1 exact caching enabled, with a script that proves byte-identical repeats return `hit_exact` at zero provider cost.
+- L2 semantic caching enabled at a 0.92 similarity threshold, with a script that proves paraphrased questions return `hit_semantic`.
+- A 30-call FAQ batch that demonstrates roughly 80% cost reduction against the uncached baseline.
+- A force-refresh header and a namespace-swap pattern you can reuse when you ship a prompt change and need to invalidate stale entries.
- FutureAGI account → [app.futureagi.com](https://app.futureagi.com)
@@ -23,70 +54,107 @@ Enable caching once in the Agent Command Center dashboard, switch the strategy t
- Python 3.9+
-## Install
+## Why this matters
+
+Your support bot's bill grows with rephrasings, not with new questions. Real users ask the same five intents a hundred different ways, and every paraphrase round-trips to the provider as a fresh paid call. Pull a day of your own request logs and the pattern is right there: ten variants of "what's your return policy?", all answered identically, all billed separately.
+
+HTTP and Redis caches don't catch this; they hash exact bodies, so paraphrases miss. Prompt-hash caches only catch byte-identical repeats, the smaller share of duplicate traffic. Agent Command Center catches both at the gateway: exact-hash for L1, embedding similarity for L2. Every response returns `x-agentcc-cache` as `miss`, `hit_exact`, or `hit_semantic`, so per-call savings show up in the request logs.
-Install the OpenAI and Agent Command Center SDKs and set your API key.
+## Install
```bash
-pip install openai agentcc
+pip install openai
```
```bash
export AGENTCC_API_KEY="sk-agentcc-your-key"
```
-## Tutorial
+The gateway is a drop-in replacement for `api.openai.com`, so no Agent Command Center SDK is required. The standard `openai` Python client points at the gateway base URL and the cache, cost, and latency headers ride along on every response.
+
+## How it works
+
+Agent Command Center sits in front of your LLM provider calls. Point your OpenAI SDK at `https://gateway.futureagi.com/v1` and every request flows through it, applying caching, routing, fallback, and cost tracking, before hitting the provider.
+
+The gateway has two cache tiers:
+
+- **L1 exact cache** hashes the full request (model, messages, temperature, all params). Byte-identical prompts return instantly.
+- **L2 semantic cache** embeds each prompt into a vector and matches paraphrases above a similarity threshold. Only runs on L1 misses.
+
+The five steps below send a baseline request, enable each tier, measure the savings on a batch, and show how to bypass cache when you need fresh answers.
-Point the OpenAI SDK at the gateway and send a request. The response headers tell you exactly what it cost and whether it came from cache.
+Before turning anything on, send one request through the gateway with caching disabled. This is your "no caching" control. Every gateway response carries `x-agentcc-cache`, `x-agentcc-cost`, and `x-agentcc-latency-ms` headers, so you can read the exact cost and latency you're paying right now and compare it to the cached numbers in the steps that follow.
```python
import os
from openai import OpenAI
-API_KEY = os.environ["AGENTCC_API_KEY"]
+api_key = os.environ.get("AGENTCC_API_KEY")
+if not api_key:
+ raise RuntimeError("Missing AGENTCC_API_KEY. Grab it from Settings → API Keys")
+# Point the standard OpenAI client at the gateway instead of api.openai.com
client = OpenAI(
- api_key=API_KEY,
+ api_key=api_key,
base_url="https://gateway.futureagi.com/v1",
)
-r = client.chat.completions.with_raw_response.create(
+# with_raw_response gives access to gateway headers alongside the completion
+response = client.chat.completions.with_raw_response.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "What is your return policy?"}],
)
-print(f"cache: {r.headers.get('x-agentcc-cache')}")
-print(f"cost: ${r.headers.get('x-agentcc-cost')}")
-print(f"latency: {r.headers.get('x-agentcc-latency-ms')}ms")
+print(f"cache: {response.headers.get('x-agentcc-cache')}")
+print(f"cost: ${response.headers.get('x-agentcc-cost')}")
+print(f"latency: {response.headers.get('x-agentcc-latency-ms')}ms")
```
-`x-agentcc-cache` is empty or `miss` on a fresh call. The cost and latency are what you'd pay every time without caching.
+Expected output:
+
+```text
+cache: miss
+cost: $0.00037
+latency: 812ms
+```
+
+The cost and latency are what you'd pay every time without caching. Note these numbers; you'll compare them against cached responses in the next steps.
+The first cache layer is **L1 exact match**. The gateway hashes the exact request (model, messages, temperature, all parameters) and stores the response under that hash. Any future request with the same hash returns the cached response without ever calling the provider. It's the cheapest, fastest layer to enable, and it kicks in automatically the moment caching is on.
+
In the dashboard, go to **Gateway → Providers → Cache** and click **Configure Cache**. Toggle:
- **Enable Response Cache**: on
-- **Default TTL**: `1h` (or whatever fits your data freshness needs)
+- **Default TTL**: `1h` (cached entries expire after an hour. Set this based on how stale your data can be before you need a fresh model call.)
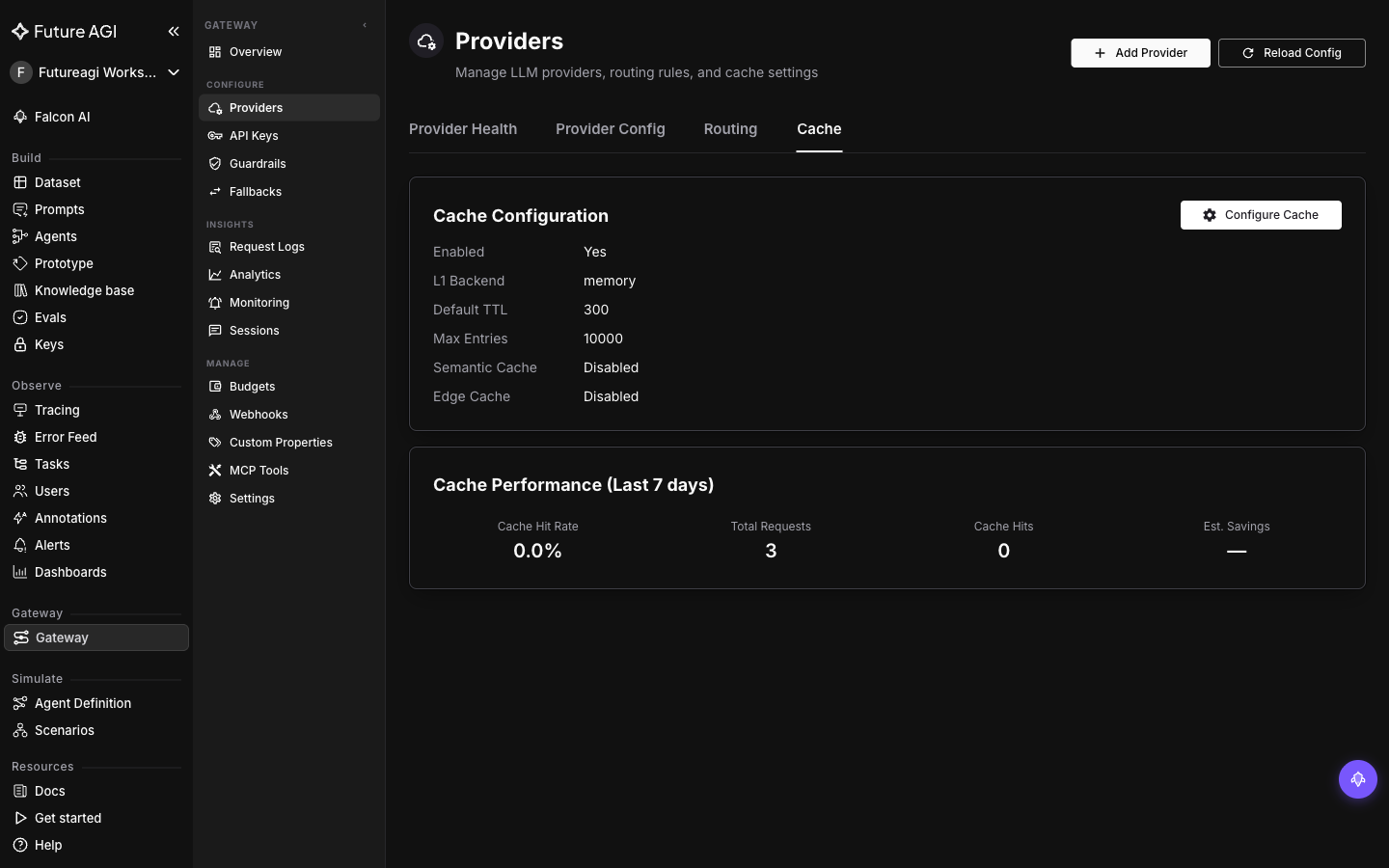 -Save. Caching is now active for every request through the gateway. The Cache Configuration card shows `Enabled: Yes` with `L1 Backend: memory` (the L1 layer is always exact-match; `memory` just means it's stored in-process. You can switch to Redis or disk for a multi-instance gateway). `Semantic Cache: Disabled` confirms only exact matches are served right now. No client change required. Run the same prompt twice:
+Verify: the Cache Configuration card should show `Enabled: Yes`, `L1 Backend: memory`, and `Semantic Cache: Disabled`. If any of these differ, save again and refresh. Run the same prompt twice:
```python
prompt = [{"role": "user", "content": "What is your return policy?"}]
-r1 = client.chat.completions.with_raw_response.create(model="gpt-4o-mini", messages=prompt)
-print(f"call 1: {r1.headers.get('x-agentcc-cache')} | ${r1.headers.get('x-agentcc-cost')}")
+first_call = client.chat.completions.with_raw_response.create(model="gpt-4o-mini", messages=prompt)
+print(f"call 1: {first_call.headers.get('x-agentcc-cache')} | ${first_call.headers.get('x-agentcc-cost')}")
-r2 = client.chat.completions.with_raw_response.create(model="gpt-4o-mini", messages=prompt)
-print(f"call 2: {r2.headers.get('x-agentcc-cache')} | ${r2.headers.get('x-agentcc-cost')}")
+# Identical prompt; should hit L1 exact cache
+second_call = client.chat.completions.with_raw_response.create(model="gpt-4o-mini", messages=prompt)
+print(f"call 2: {second_call.headers.get('x-agentcc-cache')} | ${second_call.headers.get('x-agentcc-cost')}")
```
-Call 1 is `miss`. Call 2 is `hit_exact`, instant, with `$0` provider cost. Exact caching is fast and free, but only helps when prompts are byte-identical.
+Expected output:
+
+```text
+call 1: miss | $0.00037
+call 2: hit_exact | $0.0
+```
+
+Call 2 returns the same response in under 50ms with zero provider cost. Exact caching only helps when prompts are byte-identical, meaning same model, same messages, same parameters.
Use cache **namespaces** to isolate environments or experiments. Set `x-agentcc-cache-namespace: staging` on a request to keep its cache separate from production. Each namespace is independent. A `prod` hit won't leak into `staging`.
@@ -95,106 +163,156 @@ Use cache **namespaces** to isolate environments or experiments. Set `x-agentcc-
-Real users don't ask the same question the same way twice. Semantic caching matches prompts by meaning rather than exact text. It runs as an L2 fallback after the L1 exact-match check.
+Real users don't ask the same question the same way twice. *"What is your return policy?"* and *"Can I return a product?"* are the same question to a human but byte-different to the L1 hash, so L1 alone misses both. The **L2 semantic cache** fixes that. The gateway embeds each prompt into a vector, looks for a previously-cached vector within a similarity threshold, and returns that response. L2 only runs after L1 misses, so byte-identical prompts still take the fast path.
In the same **Configure Cache** dialog, enable:
- **L2 Semantic Cache**: on
-- **Threshold**: `0.92` (similarity, 0 to 1, higher is stricter)
+- **Threshold**: `0.92` (similarity, 0 to 1, higher is stricter. 0.92 catches paraphrases without colliding unrelated questions.)
The same client code now matches paraphrases:
```python
-prompts = [
+# Same question, four different phrasings; only the first should hit the provider
+paraphrased_prompts = [
"What is your return policy?",
"Can I return a product I bought?",
"How do refunds work at your store?",
"Tell me about returning items.",
]
-for p in prompts:
- r = client.chat.completions.with_raw_response.create(
+for prompt_text in paraphrased_prompts:
+ response = client.chat.completions.with_raw_response.create(
model="gpt-4o-mini",
- messages=[{"role": "user", "content": p}],
+ messages=[{"role": "user", "content": prompt_text}],
)
- print(f"{(r.headers.get('x-agentcc-cache') or 'miss'):14} | ${r.headers.get('x-agentcc-cost')} | {p}")
+ cache_status = response.headers.get("x-agentcc-cache") or "miss"
+ cost = response.headers.get("x-agentcc-cost")
+ print(f"{cache_status:14} | ${cost} | {prompt_text}")
```
-The first prompt is `miss`; the rest are paraphrases above the 0.92 similarity threshold and come back as `hit_semantic` with near-zero cost.
+Expected output:
-
-Tune the threshold carefully. Too low (e.g., 0.7) and unrelated questions collide; too high (e.g., 0.99) and you only catch near-exact matches. Start at 0.92 and adjust based on your hit rate vs false-positive rate.
-
+```text
+miss | $0.00037 | What is your return policy?
+hit_semantic | $0.0 | Can I return a product I bought?
+hit_semantic | $0.0 | How do refunds work at your store?
+hit_semantic | $0.0 | Tell me about returning items.
+```
+
+The first prompt pays for a provider call. The rest are paraphrases above the 0.92 similarity threshold and come back as `hit_semantic` with zero cost.
+
+
+**What a bad threshold looks like.** If you set the threshold too low (say 0.7), unrelated questions start colliding. A user asks *"How do I cancel my order?"* and gets the cached answer for *"What is your return policy?"* because both are vaguely about post-purchase actions. The response is fast and cheap, and completely wrong. Start at 0.92, check your logs for `hit_semantic` on questions that shouldn't match, and raise the threshold if you see collisions.
+
-Loop over a realistic mixed batch and tally cache hits, total cost, and latency.
+Run a realistic batch where each unique question repeats several times, mimicking what your support bot or FAQ assistant sees in production. The first occurrence of each question pays the provider; every repeat hits cache.
```python
import time
from collections import Counter
-batch = [
+# 6 unique questions × 5 repeats = 30 calls, simulating a day of support traffic
+faq_batch = [
"What is your return policy?",
"Can I return a product?",
"How do I get a refund?",
"What's the shipping cost?",
"How long does shipping take?",
"Do you ship internationally?",
-] * 5 # 30 calls total
+] * 5
-tally = Counter()
+cache_tally = Counter()
total_cost = 0.0
start = time.time()
-for p in batch:
- r = client.chat.completions.with_raw_response.create(
+for prompt_text in faq_batch:
+ response = client.chat.completions.with_raw_response.create(
model="gpt-4o-mini",
- messages=[{"role": "user", "content": p}],
+ messages=[{"role": "user", "content": prompt_text}],
)
- tally[r.headers.get("x-agentcc-cache") or "miss"] += 1
- total_cost += float(r.headers.get("x-agentcc-cost") or 0)
+ cache_tally[response.headers.get("x-agentcc-cache") or "miss"] += 1
+ total_cost += float(response.headers.get("x-agentcc-cost") or 0)
-print(f"cache results: {tally}")
+print(f"cache results: {cache_tally}")
print(f"total cost: ${total_cost:.5f}")
print(f"wall time: {time.time() - start:.1f}s")
```
-Expect ~80% hits after the first pass over each unique question (`hit_exact` for byte-identical, `hit_semantic` for paraphrases). Compare the total cost against the same batch with caching disabled. That's your savings.
+Expected output (numbers will vary with your provider pricing):
+
+```text
+cache results: Counter({'hit_semantic': 16, 'hit_exact': 8, 'miss': 6})
+total cost: $0.00222
+wall time: 14.3s
+```
+
+6 unique questions × 5 repeats = 30 calls. Only the 6 first-seen prompts hit the provider. The rest are cache hits, split between `hit_exact` for byte-identical repeats and `hit_semantic` for paraphrases. Compare against 30 uncached calls at ~$0.00037 each ($0.0111 total) and you're looking at roughly 80% savings.
+
+
-Save. Caching is now active for every request through the gateway. The Cache Configuration card shows `Enabled: Yes` with `L1 Backend: memory` (the L1 layer is always exact-match; `memory` just means it's stored in-process. You can switch to Redis or disk for a multi-instance gateway). `Semantic Cache: Disabled` confirms only exact matches are served right now. No client change required. Run the same prompt twice:
+Verify: the Cache Configuration card should show `Enabled: Yes`, `L1 Backend: memory`, and `Semantic Cache: Disabled`. If any of these differ, save again and refresh. Run the same prompt twice:
```python
prompt = [{"role": "user", "content": "What is your return policy?"}]
-r1 = client.chat.completions.with_raw_response.create(model="gpt-4o-mini", messages=prompt)
-print(f"call 1: {r1.headers.get('x-agentcc-cache')} | ${r1.headers.get('x-agentcc-cost')}")
+first_call = client.chat.completions.with_raw_response.create(model="gpt-4o-mini", messages=prompt)
+print(f"call 1: {first_call.headers.get('x-agentcc-cache')} | ${first_call.headers.get('x-agentcc-cost')}")
-r2 = client.chat.completions.with_raw_response.create(model="gpt-4o-mini", messages=prompt)
-print(f"call 2: {r2.headers.get('x-agentcc-cache')} | ${r2.headers.get('x-agentcc-cost')}")
+# Identical prompt; should hit L1 exact cache
+second_call = client.chat.completions.with_raw_response.create(model="gpt-4o-mini", messages=prompt)
+print(f"call 2: {second_call.headers.get('x-agentcc-cache')} | ${second_call.headers.get('x-agentcc-cost')}")
```
-Call 1 is `miss`. Call 2 is `hit_exact`, instant, with `$0` provider cost. Exact caching is fast and free, but only helps when prompts are byte-identical.
+Expected output:
+
+```text
+call 1: miss | $0.00037
+call 2: hit_exact | $0.0
+```
+
+Call 2 returns the same response in under 50ms with zero provider cost. Exact caching only helps when prompts are byte-identical, meaning same model, same messages, same parameters.
Use cache **namespaces** to isolate environments or experiments. Set `x-agentcc-cache-namespace: staging` on a request to keep its cache separate from production. Each namespace is independent. A `prod` hit won't leak into `staging`.
@@ -95,106 +163,156 @@ Use cache **namespaces** to isolate environments or experiments. Set `x-agentcc-
-Real users don't ask the same question the same way twice. Semantic caching matches prompts by meaning rather than exact text. It runs as an L2 fallback after the L1 exact-match check.
+Real users don't ask the same question the same way twice. *"What is your return policy?"* and *"Can I return a product?"* are the same question to a human but byte-different to the L1 hash, so L1 alone misses both. The **L2 semantic cache** fixes that. The gateway embeds each prompt into a vector, looks for a previously-cached vector within a similarity threshold, and returns that response. L2 only runs after L1 misses, so byte-identical prompts still take the fast path.
In the same **Configure Cache** dialog, enable:
- **L2 Semantic Cache**: on
-- **Threshold**: `0.92` (similarity, 0 to 1, higher is stricter)
+- **Threshold**: `0.92` (similarity, 0 to 1, higher is stricter. 0.92 catches paraphrases without colliding unrelated questions.)
The same client code now matches paraphrases:
```python
-prompts = [
+# Same question, four different phrasings; only the first should hit the provider
+paraphrased_prompts = [
"What is your return policy?",
"Can I return a product I bought?",
"How do refunds work at your store?",
"Tell me about returning items.",
]
-for p in prompts:
- r = client.chat.completions.with_raw_response.create(
+for prompt_text in paraphrased_prompts:
+ response = client.chat.completions.with_raw_response.create(
model="gpt-4o-mini",
- messages=[{"role": "user", "content": p}],
+ messages=[{"role": "user", "content": prompt_text}],
)
- print(f"{(r.headers.get('x-agentcc-cache') or 'miss'):14} | ${r.headers.get('x-agentcc-cost')} | {p}")
+ cache_status = response.headers.get("x-agentcc-cache") or "miss"
+ cost = response.headers.get("x-agentcc-cost")
+ print(f"{cache_status:14} | ${cost} | {prompt_text}")
```
-The first prompt is `miss`; the rest are paraphrases above the 0.92 similarity threshold and come back as `hit_semantic` with near-zero cost.
+Expected output:
-
-Tune the threshold carefully. Too low (e.g., 0.7) and unrelated questions collide; too high (e.g., 0.99) and you only catch near-exact matches. Start at 0.92 and adjust based on your hit rate vs false-positive rate.
-
+```text
+miss | $0.00037 | What is your return policy?
+hit_semantic | $0.0 | Can I return a product I bought?
+hit_semantic | $0.0 | How do refunds work at your store?
+hit_semantic | $0.0 | Tell me about returning items.
+```
+
+The first prompt pays for a provider call. The rest are paraphrases above the 0.92 similarity threshold and come back as `hit_semantic` with zero cost.
+
+
+**What a bad threshold looks like.** If you set the threshold too low (say 0.7), unrelated questions start colliding. A user asks *"How do I cancel my order?"* and gets the cached answer for *"What is your return policy?"* because both are vaguely about post-purchase actions. The response is fast and cheap, and completely wrong. Start at 0.92, check your logs for `hit_semantic` on questions that shouldn't match, and raise the threshold if you see collisions.
+
-Loop over a realistic mixed batch and tally cache hits, total cost, and latency.
+Run a realistic batch where each unique question repeats several times, mimicking what your support bot or FAQ assistant sees in production. The first occurrence of each question pays the provider; every repeat hits cache.
```python
import time
from collections import Counter
-batch = [
+# 6 unique questions × 5 repeats = 30 calls, simulating a day of support traffic
+faq_batch = [
"What is your return policy?",
"Can I return a product?",
"How do I get a refund?",
"What's the shipping cost?",
"How long does shipping take?",
"Do you ship internationally?",
-] * 5 # 30 calls total
+] * 5
-tally = Counter()
+cache_tally = Counter()
total_cost = 0.0
start = time.time()
-for p in batch:
- r = client.chat.completions.with_raw_response.create(
+for prompt_text in faq_batch:
+ response = client.chat.completions.with_raw_response.create(
model="gpt-4o-mini",
- messages=[{"role": "user", "content": p}],
+ messages=[{"role": "user", "content": prompt_text}],
)
- tally[r.headers.get("x-agentcc-cache") or "miss"] += 1
- total_cost += float(r.headers.get("x-agentcc-cost") or 0)
+ cache_tally[response.headers.get("x-agentcc-cache") or "miss"] += 1
+ total_cost += float(response.headers.get("x-agentcc-cost") or 0)
-print(f"cache results: {tally}")
+print(f"cache results: {cache_tally}")
print(f"total cost: ${total_cost:.5f}")
print(f"wall time: {time.time() - start:.1f}s")
```
-Expect ~80% hits after the first pass over each unique question (`hit_exact` for byte-identical, `hit_semantic` for paraphrases). Compare the total cost against the same batch with caching disabled. That's your savings.
+Expected output (numbers will vary with your provider pricing):
+
+```text
+cache results: Counter({'hit_semantic': 16, 'hit_exact': 8, 'miss': 6})
+total cost: $0.00222
+wall time: 14.3s
+```
+
+6 unique questions × 5 repeats = 30 calls. Only the 6 first-seen prompts hit the provider. The rest are cache hits, split between `hit_exact` for byte-identical repeats and `hit_semantic` for paraphrases. Compare against 30 uncached calls at ~$0.00037 each ($0.0111 total) and you're looking at roughly 80% savings.
+
+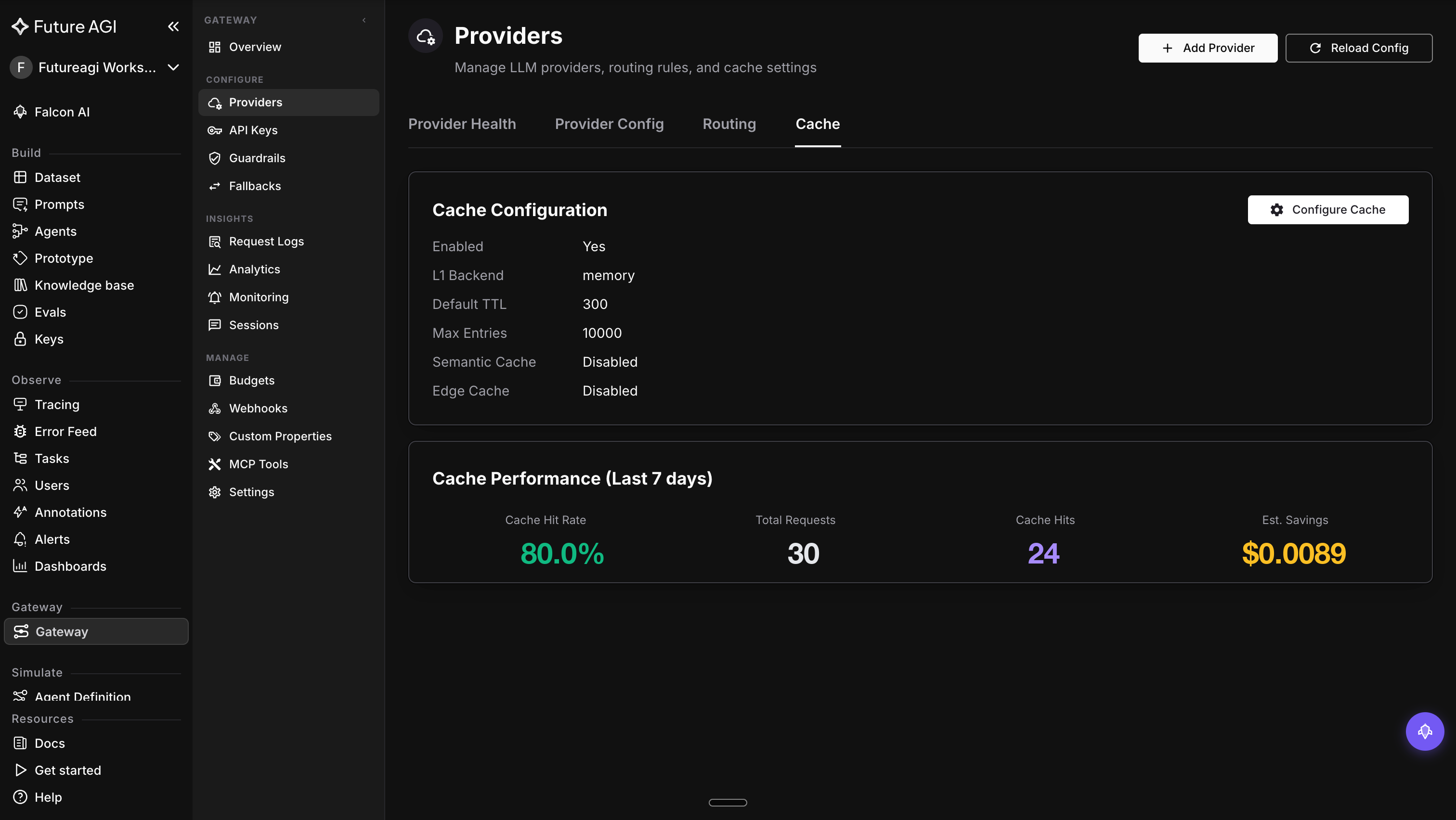 +
+The Cache Performance panel is where the savings live in production: hit rate, hits, requests, and estimated savings over the last 7 days. Your exact numbers will differ with your own traffic, but the panel shape is what you'll watch climb after enabling each tier.
-When you change a system prompt or want a fresh response for a specific call, send `x-agentcc-cache-force-refresh: true` on that request. The gateway skips the cache read but still writes the new response back, so subsequent calls hit the refreshed entry.
+Two situations where you need to skip the cache: testing a prompt change, or invalidating stale entries after shipping a fix.
+
+For one-off bypass, send `x-agentcc-cache-force-refresh: true`. The gateway skips the cache read but writes the new response back, so subsequent calls hit the refreshed entry.
```python
-r = client.chat.completions.with_raw_response.create(
+# Skip cache read, but write the fresh response back for future hits
+response = client.chat.completions.with_raw_response.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "What is your return policy?"}],
extra_headers={"x-agentcc-cache-force-refresh": "true"},
)
-print(f"forced refresh: {r.headers.get('x-agentcc-cache')}") # miss, then re-cached
+print(f"forced refresh: {response.headers.get('x-agentcc-cache')}")
```
+Expected output:
+
+```text
+forced refresh: miss
+```
+
+The gateway skipped the cache read but wrote the new response back, so subsequent identical calls hit the refreshed entry.
+
For a global wipe after a prompt-template update, route your traffic to a fresh namespace by setting `x-agentcc-cache-namespace: support-v2` instead of `support`. The old cache stays available to anything still pointed at `support`.
+
+The Cache Performance panel is where the savings live in production: hit rate, hits, requests, and estimated savings over the last 7 days. Your exact numbers will differ with your own traffic, but the panel shape is what you'll watch climb after enabling each tier.
-When you change a system prompt or want a fresh response for a specific call, send `x-agentcc-cache-force-refresh: true` on that request. The gateway skips the cache read but still writes the new response back, so subsequent calls hit the refreshed entry.
+Two situations where you need to skip the cache: testing a prompt change, or invalidating stale entries after shipping a fix.
+
+For one-off bypass, send `x-agentcc-cache-force-refresh: true`. The gateway skips the cache read but writes the new response back, so subsequent calls hit the refreshed entry.
```python
-r = client.chat.completions.with_raw_response.create(
+# Skip cache read, but write the fresh response back for future hits
+response = client.chat.completions.with_raw_response.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "What is your return policy?"}],
extra_headers={"x-agentcc-cache-force-refresh": "true"},
)
-print(f"forced refresh: {r.headers.get('x-agentcc-cache')}") # miss, then re-cached
+print(f"forced refresh: {response.headers.get('x-agentcc-cache')}")
```
+Expected output:
+
+```text
+forced refresh: miss
+```
+
+The gateway skipped the cache read but wrote the new response back, so subsequent identical calls hit the refreshed entry.
+
For a global wipe after a prompt-template update, route your traffic to a fresh namespace by setting `x-agentcc-cache-namespace: support-v2` instead of `support`. The old cache stays available to anything still pointed at `support`.
+## Troubleshooting
+
+| Symptom | Likely cause | Fix | Verify |
+|---|---|---|---|
+| `x-agentcc-cache` header missing from response | Request isn't going through the gateway | Confirm `base_url` is `https://gateway.futureagi.com/v1`, not the provider URL directly | Re-run; `response.headers["x-agentcc-cache"]` is set |
+| Every call returns `miss` even for identical prompts | Caching not enabled, or TTL expired | Check **Gateway → Providers → Cache** shows `Enabled: Yes`. Increase TTL if entries expire before repeats arrive | Send the same prompt twice; second call returns `hit_exact` |
+| Semantic cache returns wrong answer for a different question | Similarity threshold too low | Raise the threshold from your current value toward 0.95. Test with a pair of questions that should *not* match | Two unrelated questions both return `miss` on first call |
+| `hit_semantic` returns a stale answer after you changed the system prompt | Old response still cached under the previous embedding | Send `x-agentcc-cache-force-refresh: true` once, or switch to a new cache namespace | Next call returns the new system-prompt output |
+| `401 Unauthorized` on every request | API key wrong or missing the `sk-agentcc-` prefix | Re-export `AGENTCC_API_KEY` and confirm it starts with `sk-agentcc-` in Settings → API Keys | Baseline request from Step 1 returns a 200 with `x-agentcc-cost` |
+
+## What you built
+
-You enabled exact then semantic caching in the dashboard, watched paraphrased prompts return cached responses with `x-agentcc-cache: hit_semantic`, and measured the cost drop on a realistic batch, without changing application code beyond pointing at the gateway.
+Exact + semantic caching at the gateway, paraphrased duplicates returning cached answers with zero provider cost, and a way to force-refresh or namespace-switch when you ship prompt changes.
-## Explore further
-
-
-
- Cache modes, TTL, invalidation, and per-org configuration
-
-
- Weighted routing, fallback, and cost-optimized strategies
-
-
- Per-request cost reporting and budget alerts
-
-
+- L1 exact cache catches byte-identical repeats
+- L2 semantic cache catches paraphrased duplicates above a similarity threshold
+- `x-agentcc-cache`, `x-agentcc-cost`, `x-agentcc-latency-ms` headers on every response for auditing hit rates
+- Per-request bypass with `x-agentcc-cache-force-refresh` and bulk invalidation via cache namespaces
+
+## Next steps
+
+Once the baseline cookbook runs, the next technical moves on the same gateway:
+
+1. **Wire `x-agentcc-cache-force-refresh: true` into your prompt-update CI** so that every deploy that changes a system prompt sends one forced refresh per top-N FAQ question, repopulating the cache with the new answers before users hit stale entries.
+2. **Add per-environment namespaces** (`staging`, `prod`, `support-v2`) on the request header so a canary deploy can build its own cache against a fresh slice of traffic without polluting prod.
+3. **Tune the similarity threshold against your own logs.** Export 200 production prompts from the gateway, replay them through L2 at 0.90, 0.92, and 0.95, and pick the threshold with the highest hit rate and zero observed collisions.
+4. **Add a routing policy on top of the cache.** Configure Agent Command Center to send cache misses to a cheaper fallback model when the primary is rate-limited. See [Routing & Reliability](/docs/command-center/features/routing).
+
+Reference: [Caching feature docs](/docs/command-center/features/caching) for the full set of cache modes, TTL options, and per-org configuration.