diff --git a/ja/use-dify/getting-started/quick-start.mdx b/ja/use-dify/getting-started/quick-start.mdx
index 67626bc06..a1b890513 100644
--- a/ja/use-dify/getting-started/quick-start.mdx
+++ b/ja/use-dify/getting-started/quick-start.mdx
@@ -230,21 +230,21 @@ description: "サンプルアプリを通じてDifyを深く理解"
2. **フィルタ条件**を有効にします:`{x}type` **に** `Doc`。
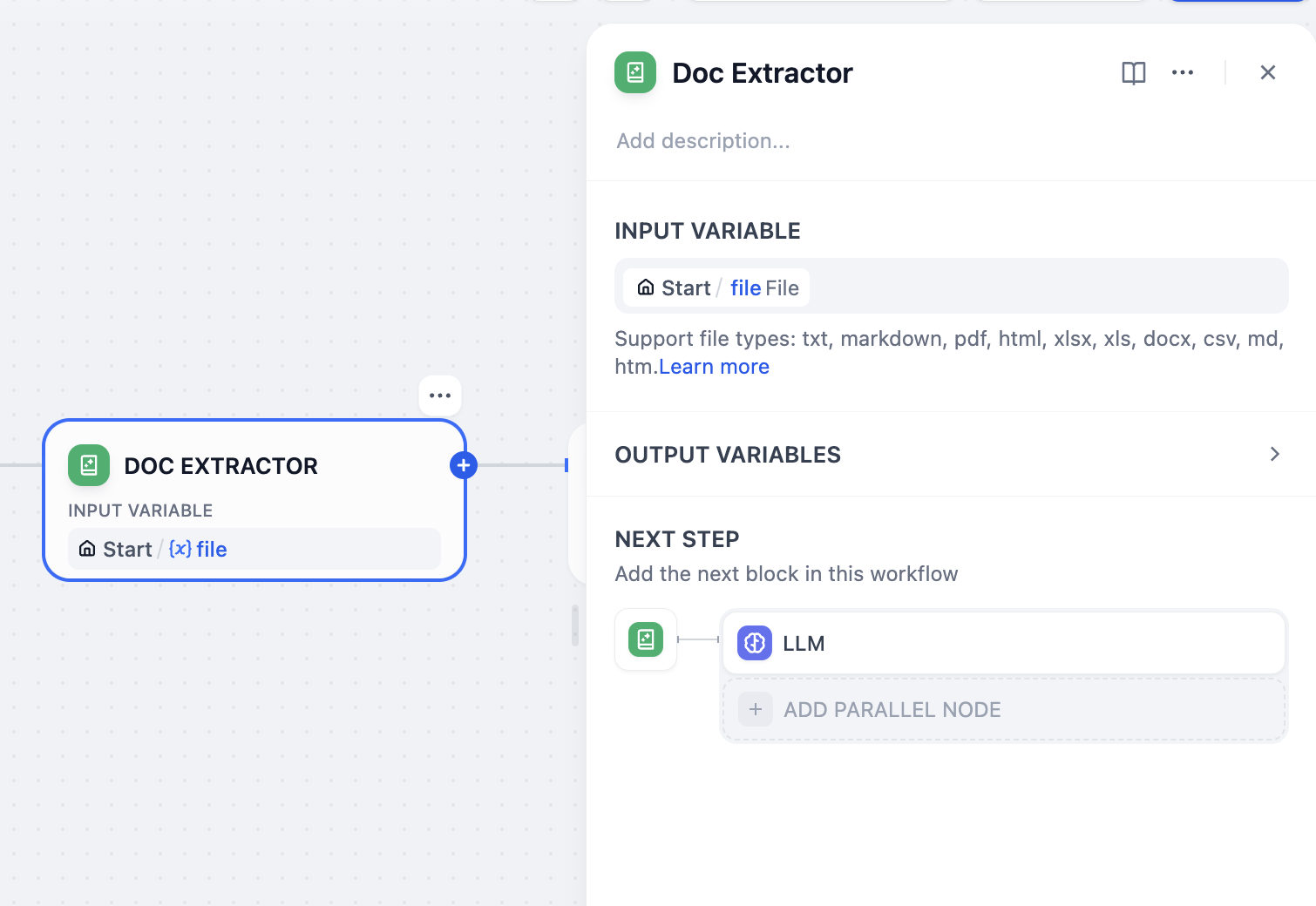
-### 5. ドキュメントからテキストを抽出:ドキュメント抽出器ノード
+### 5. ドキュメントからテキストを抽出:テキスト抽出ノード
`gpt-5.2`はPDFやDOCXなどのアップロードされたドキュメントを直接読むことはできないため、まずプレーンテキストに変換する必要があります。
- これがまさにドキュメント抽出器ノードが行うことです。ドキュメントファイルを入力として受け取り、次のステップのためにクリーンで使用可能なテキストを出力します。
+ これがまさにテキスト抽出ノードが行うことです。ドキュメントファイルを入力として受け取り、次のステップのためにクリーンで使用可能なテキストを出力します。
- 
+ 
-1. ドキュメントノードの後に、ドキュメント抽出器ノードを追加します。
+1. ドキュメントノードの後に、テキスト抽出ノードを追加します。
-2. ドキュメント抽出器ノードのパネルで、`Document/result`を入力変数として設定します。
+2. テキスト抽出ノードのパネルで、`Document/result`を入力変数として設定します。
### 6. すべての参考資料を統合:LLMノード
@@ -258,7 +258,7 @@ description: "サンプルアプリを通じてDifyを深く理解"

-1. ドキュメント抽出器ノードの後に、LLMノードを追加します。
+1. テキスト抽出ノードの後に、LLMノードを追加します。
2. 画像ノードもこのLLMノードに接続します。
diff --git a/ja/use-dify/knowledge/knowledge-pipeline/knowledge-pipeline-orchestration.mdx b/ja/use-dify/knowledge/knowledge-pipeline/knowledge-pipeline-orchestration.mdx
index 11a221d2a..4d95875b8 100644
--- a/ja/use-dify/knowledge/knowledge-pipeline/knowledge-pipeline-orchestration.mdx
+++ b/ja/use-dify/knowledge/knowledge-pipeline/knowledge-pipeline-orchestration.mdx
@@ -211,7 +211,7 @@ Google Drive、Dropbox、OneDriveなどのクラウドストレージサービ
PDF、XLSX、DOCXなど多様な形式のドキュメントが存在しますが、LLMはこれらをそのまま扱えません。そのため、抽出器(Extractor)が各種ファイルを解析・変換し、LLMが扱いやすい形式に変換します。
-Difyのドキュメント抽出器、あるいはMarketplaceから「Dify Extractor」「Unstructured」等のツールを選択できます。
+Difyのテキスト抽出ノード、あるいはMarketplaceから「Dify Extractor」「Unstructured」等のツールを選択できます。
@@ -238,7 +238,7 @@ Difyのドキュメント抽出器、あるいはMarketplaceから「Dify Extrac
-#### Doc Extractor(ドキュメント抽出器)
+#### Doc Extractor(テキスト抽出)

@@ -247,7 +247,7 @@ Difyのドキュメント抽出器、あるいはMarketplaceから「Dify Extrac
情報処理の中核となり、入力変数からファイルを識別・読取・情報抽出を行い、次のノードで利用できる形式へ変換します。
-詳細は[ドキュメント抽出器](/ja/use-dify/nodes/doc-extractor)をご参照ください。
+詳細は[テキスト抽出](/ja/use-dify/nodes/doc-extractor)をご参照ください。
#### Dify Extractor
diff --git a/ja/use-dify/nodes/doc-extractor.mdx b/ja/use-dify/nodes/doc-extractor.mdx
index 31fc3d887..e43546067 100644
--- a/ja/use-dify/nodes/doc-extractor.mdx
+++ b/ja/use-dify/nodes/doc-extractor.mdx
@@ -1,15 +1,15 @@
---
-title: "ドキュメントエクストラクター"
+title: "テキスト抽出"
description: "AI処理のためにアップロードされたドキュメントからテキストコンテンツを抽出"
---
⚠️ このドキュメントは AI によって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/doc-extractor) を参照してください。
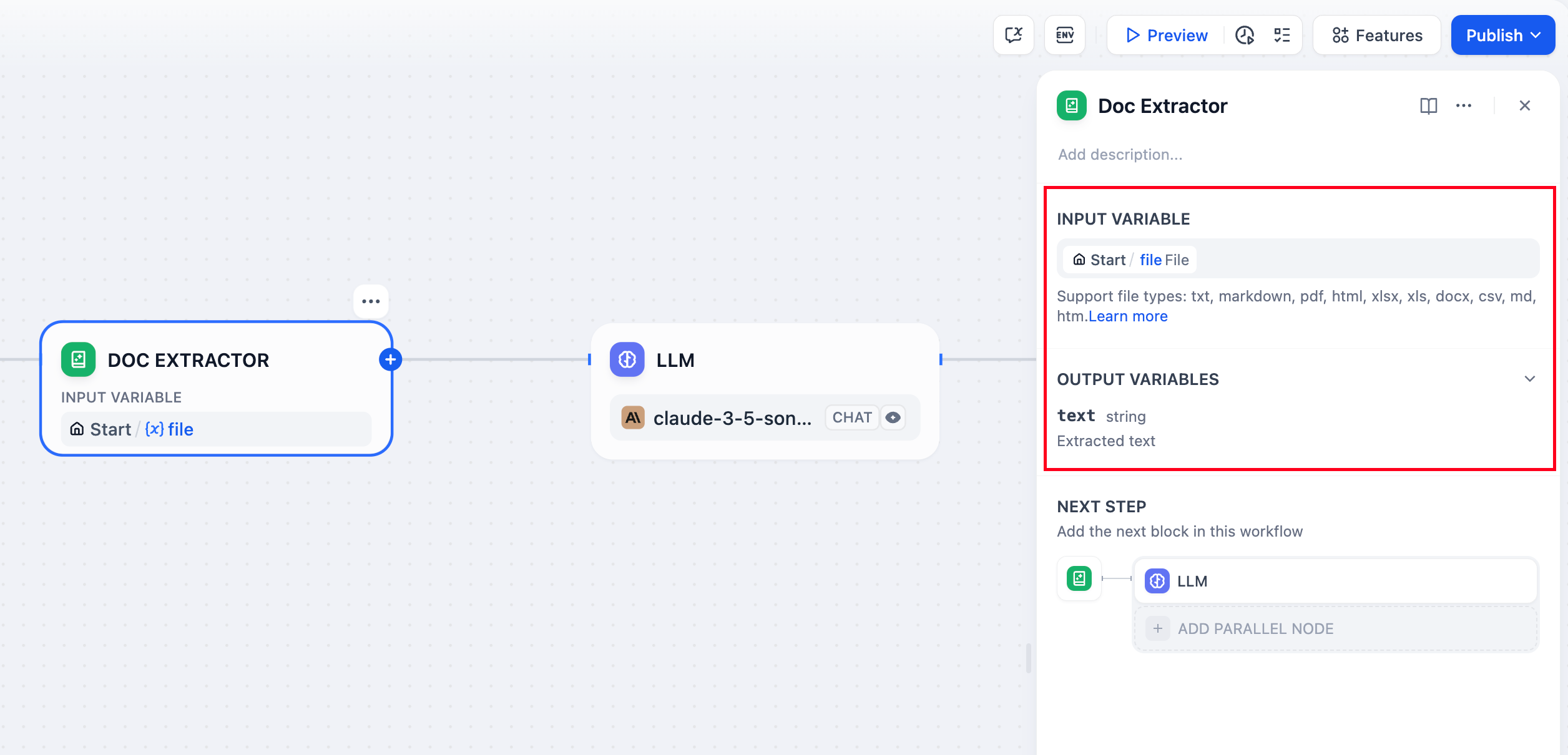
-ドキュメントエクストラクターノードは、アップロードされたファイルを大規模言語モデルが処理できるテキストに変換します。言語モデルはPDFやDOCXなどのドキュメント形式を直接読み取ることができないため、このノードはファイルアップロードとAI分析の間の重要な橋渡し役を果たします。
+テキスト抽出ノードは、アップロードされたファイルを大規模言語モデルが処理できるテキストに変換します。言語モデルはPDFやDOCXなどのドキュメント形式を直接読み取ることができないため、このノードはファイルアップロードとAI分析の間の重要な橋渡し役を果たします。
-
- 
+
+ 
## サポートされているファイル形式
@@ -55,7 +55,7 @@ description: "AI処理のためにアップロードされたドキュメント
## 実装例
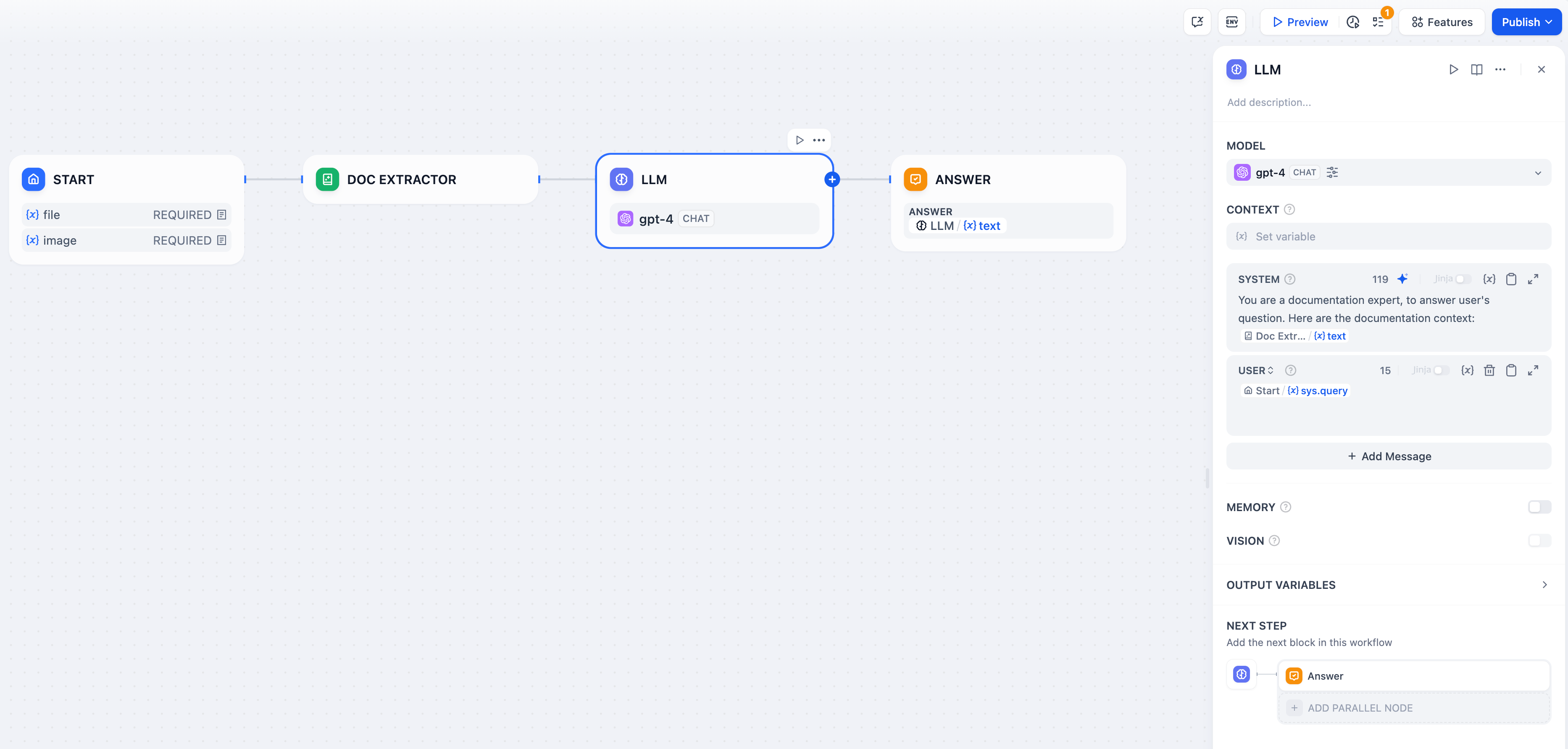
-ドキュメントエクストラクターを使用した完全なドキュメントQ&Aワークフローの例です:
+テキスト抽出ノードを使用した完全なドキュメントQ&Aワークフローの例です:
@@ -65,7 +65,7 @@ description: "AI処理のためにアップロードされたドキュメント
**ファイルアップロード設定** - ユーザーからのドキュメントアップロードを受け入れるために、Startノードでファイル入力を有効にします。
-**テキスト抽出** - ドキュメントエクストラクターを接続して、アップロードされたファイルを処理し、テキストコンテンツを抽出します。
+**テキスト抽出** - テキスト抽出ノードを接続して、アップロードされたファイルを処理し、テキストコンテンツを抽出します。
**AI処理** - 抽出されたテキストを大規模言語モデルのプロンプトで分析、要約、または質問応答に使用します。
@@ -89,7 +89,7 @@ description: "AI処理のためにアップロードされたドキュメント
## 処理の考慮事項
-ドキュメントエクストラクターは、異なるファイル形式に最適化された特殊な解析ライブラリを使用します。可能な限りテキスト構造と書式を保持し、抽出されたコンテンツを大規模言語モデル処理により有用にします。
+テキスト抽出ノードは、異なるファイル形式に最適化された特殊な解析ライブラリを使用します。可能な限りテキスト構造と書式を保持し、抽出されたコンテンツを大規模言語モデル処理により有用にします。
### ファイル形式処理
diff --git a/ja/use-dify/nodes/user-input.mdx b/ja/use-dify/nodes/user-input.mdx
index 405c741c9..34519f0cd 100644
--- a/ja/use-dify/nodes/user-input.mdx
+++ b/ja/use-dify/nodes/user-input.mdx
@@ -101,7 +101,7 @@ description: "ワークフローとチャットフローアプリケーション
ユーザー入力ノードはファイルを収集するだけで、コンテンツを読み取ったり解析したりしないため、アップロードされたファイルは後続のノードによって適切に処理される必要があります。例えば:
-- ドキュメントファイルは、LLM がそのコンテンツを理解できるように、テキスト抽出のためにドキュメント抽出器ノードにルーティングできます。
+- ドキュメントファイルは、LLM がそのコンテンツを理解できるように、テキスト抽出ノードにルーティングできます。
- 画像は、ビジョン機能を持つ LLM ノードまたは専用の画像処理ツールノードに送信できます。
diff --git a/ja/use-dify/tutorials/article-reader.mdx b/ja/use-dify/tutorials/article-reader.mdx
index 22f11d8c4..0c90ed093 100644
--- a/ja/use-dify/tutorials/article-reader.mdx
+++ b/ja/use-dify/tutorials/article-reader.mdx
@@ -34,13 +34,13 @@ DifyでChatflowを作成し、モデルプロバイダーを追加して、十
ビジネスシーンに応じて、適切なファイルアップロード方法を選択してください。
-### **テキスト抽出ツール**
+### **テキスト抽出**
LLMはファイルを直接読み取ることができません。これは、多くのユーザーがファイルアップロード機能を初めて使用する際に抱く誤解であり、ファイルを変数としてLLMノードに適用すればよいと考えがちですが、実際にはLLMが読み取る内容は何もありません。
-そのため、Difyではテキスト抽出ツールを導入しており、このノードはファイル変数からテキストを抽出し、テキスト形式の変数を出力します。
+そのため、Difyではテキスト抽出ノードを導入しており、このノードはファイル変数からテキストを抽出し、テキスト形式の変数を出力します。
-開始ノードのファイル変数を入力として、テキスト抽出ツールはドキュメント形式のファイルをテキスト形式の変数に変換します。
+開始ノードのファイル変数を入力として、テキスト抽出ノードはドキュメント形式のファイルをテキスト形式の変数に変換します。