{kind=link}
One endpoint. More free AI than any single provider. Less rate limit headaches.
Don't want to pay
# Your existing code works. Just change the URL.
client = OpenAI(base_url="http://localhost:8000/v1", api_key="fake")
No code changes. No retry logic. No 429 errors breaking your app.
Free AI APIs are powerful—but using them directly is painful:
❌ Groq hits rate limit → Your app crashes
❌ Gemini quota exhausted → User sees error
❌ Switching providers → Rewrite your integration
❌ Testing 5 providers → 5 different SDKs to manage
✅ Gemini fails → Automatically tries Groq
✅ One provider down → Traffic routes to others
✅ Same API for everyone → OpenAI-compatible
✅ More providers = More throughput
You get a meta-model: a single endpoint that routes to the best available free provider, handles failures automatically, and keeps your app running.
| Feature | Why It Matters |
|---|---|
| OpenAI-compatible | Drop-in for your existing code. LangChain, LlamaIndex, any SDK. |
| Any free providers | Gemini, Groq, Mistral, Cerebras, Ollama, etc. |
| Automatic failover | Provider down? One model hit limits? We try the next one, round-robin or random or by your preferences. Zero downtime. |
| Circuit breakers | Bad provider? Quarantined automatically. |
| Rate limit management | Built-in quota tracking. No external dependencies. |
| Real-time streaming | SSE streaming from every provider. |
| Local models | Mix cloud free tiers with your local Ollama instance. |
| User | Use Case |
|---|---|
| Independent developers | Ship AI features without a $$$/month API bill |
| Students & hobbyists | GPT-level AI, no need credit card or phone number |
| Self-hosters | Combine Ollama privacy with cloud capacity |
| Researchers | Batch queries across providers for higher throughput |
git clone https://github.com/msmarkgu/RelayFreeLLM.git
cd RelayFreeLLM
pip install -r requirements.txtCreate a .env file:
GEMINI_APIKEY= # ai.google.dev
GROQ_APIKEY= # console.groq.com
MISTRAL_APIKEY= # console.mistral.ai
CEREBRAS_APIKEY= # cloud.cerebras.ai
# any other providers you have
#ABC_APIKEY=...
#XYZ_APIKEY=...
#Best_APIKEY=...
# OLLMA model you host locally
#OLLAMA_BASE_URL=http://localhost:11434 # optional
# tell RelayFreeLLM how to choose from providers and provided models.
# default strategy is roundrobin for both.
PROVIDER_STRATEGY=roundrobin # pick provider in turn
MODEL_STRATEGY=random # randomly pick a model of the currently selected providerpython -m tests.test_models_availabilitypython -m src.serverPython SDK:
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="relay-free"
)
# Automatic routing - picks the best available
response = client.chat.completions.create(
model="meta-model",
messages=[{"role": "user", "content": "Hello!"}]
)
# Or route to specific provider
response = client.chat.completions.create(
model="groq/llama-3.3-70b-versatile",
messages=[{"role": "user", "content": "Hello!"}]
)cURL:
curl -X POST http://localhost:8000/v1/chat/completions \
-H "Authorization: Bearer relay-free" \
-H "Content-Type: application/json" \
-d '{"model": "meta-model", "messages": [{"role": "user", "content": "Hi"}]}'LangChain:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
base_url="http://localhost:8000/v1",
api_key="relay-free",
model="meta-model"
)Tell RelayFreeLLM what you need:
// "Any model from any providers, RelayFreeLLM will choose one"
{"model": "meta-model", "messages": [...]}
// "Give me coding model from any providers"
{"model": "meta-model", "model_type": "coding", "messages": [...]}
// "I prefer small models to run fast, give simple responses"
{"model": "meta-model", "model_scale": "small", "messages": [...]}
// "I want large models to do most capable reasoning"
{"model": "meta-model", "model_scale": "large", "messages": [...]}
// "I want DeepSeek models if available"
{"model": "meta-model", "model_name": "deepseek", "messages": [...]}
// "Specific provider/model"
{"model": "Gemini/gemini-2.5-flash", "messages": [...]}When a provider hits a rate limit:
Request → Groq (rate limited)
→ Circuit breaker activates
→ Retry → Gemini
→ Retry → Mistral
→ Success ✓
| Parameter | Type | Description |
|---|---|---|
model |
string | "meta-model" for auto-routing, or "provider/model" for direct |
messages |
array | Standard OpenAI message format |
stream |
bool | Enable SSE streaming (default: false) |
model_type |
string | Filter: text, coding, ocr |
model_scale |
string | Filter: large, medium, small |
model_name |
string | Match model name substring |
List available models with status:
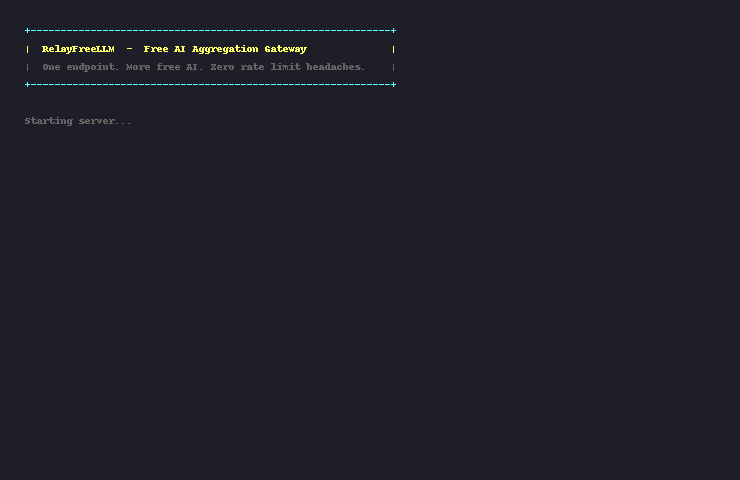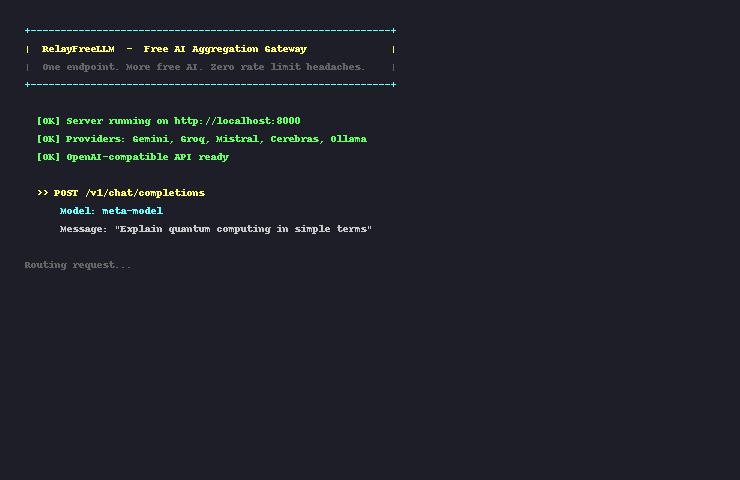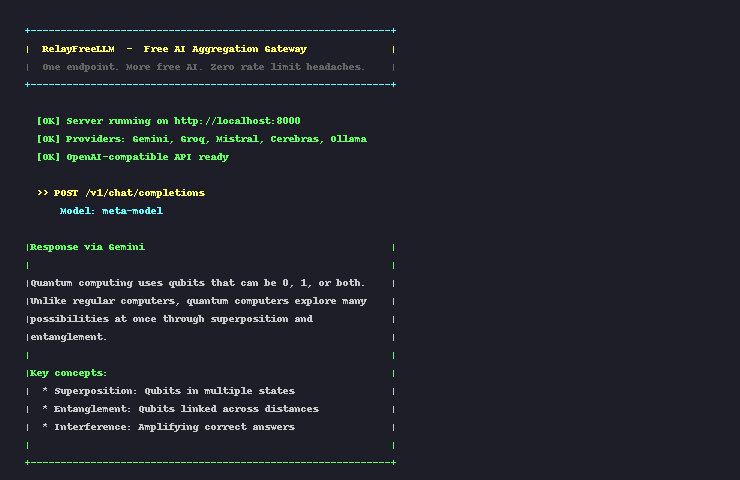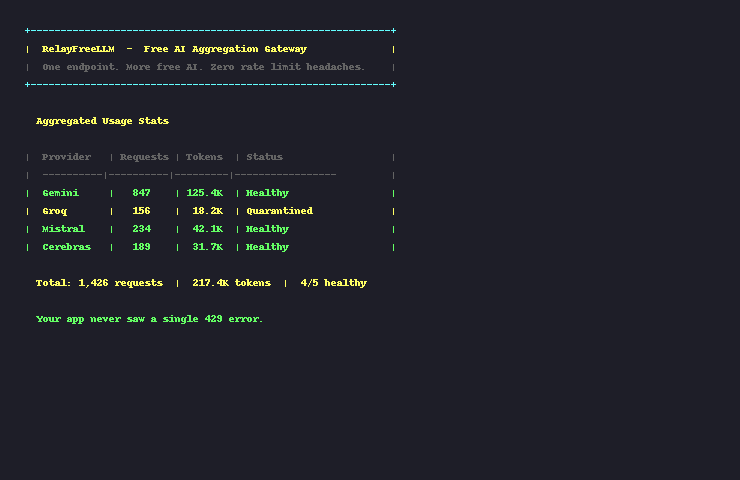
curl http://localhost:8000/v1/models?type=coding&scale=largeTrack your aggregated usage:
curl http://localhost:8000/v1/usage┌─────────────────────────────────────────────────┐
│ Your Application │
│ (OpenAI SDK, LangChain, etc.) │
└─────────────────────┬───────────────────────────┘
│ OpenAI-compatible API
┌─────────────────────▼───────────────────────────┐
│ RelayFreeLLM Gateway │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────┐ │
│ │ Router │→ │ Dispatcher │→ │ Selector│ │
│ │ /v1/chat │ │ (retries) │ │ (quota) │ │
│ └─────────────┘ └─────────────┘ └────┬────┘ │
└─────────────────────────────────────────┼───────┘
│
┌──────────┬──────────┬───────────┼──────────┐
▼ ▼ ▼ ▼ ▼
┌────────┐ ┌────────┐ ┌────────┐ ┌────────┐ ┌───────┐
│ Gemini │ │ Groq │ │ Mistral│ │Cerebras│ │ Ollama│
└────────┘ └────────┘ └────────┘ └────────┘ └───────┘
RelayFreeLLM/
├── src/
│ ├── server.py # Entry point
│ ├── router.py # API endpoints
│ ├── model_dispatcher.py # Retry & circuit breaker logic
│ ├── model_selector.py # Quota-aware routing
│ ├── provider_registry.py # Auto-discovers providers
│ ├── models.py # Request/response models
│ └── api_clients/ # Provider implementations
│ ├── gemini_client.py
│ ├── groq_client.py
│ ├── mistral_client.py
│ └── ...
├── tests/ # Unit & integration tests
└── provider_model_limits.json # Rate limit configuration
- Web dashboard for live provider status
- Persistent rate limit state
- Prompt caching layer
- Embeddings & image generation routing
- One-command Docker deploy
Found a new free provider? Adding one takes about 50 lines:
# src/api_clients/my_provider_client.py
class MyProviderClient(ApiInterface):
PROVIDER_NAME = "myprovider"
async def call_model_api(self, request, stream):
# Your API logic here
passPRs welcome.
Built with FastAPI, Pydantic, and httpx.
Powered by the generous free tiers of Google Gemini, Groq, Mistral AI, Cerebras, and Ollama.
Built for developers who want great AI without the bill.